Einzelprojekte
Unsere derzeit 14 geförderten Einzelprojekten sind Kooperationen zwischen jeweils zwei Arbeitsgruppen, die verschiedene Bereiche oder Disziplinen abdecken. Ziel ist die Förderung des vertieften Austausches zwischen verschiedenen wissenschaftlichen Disziplinen.
FORSCHUNGSBEREICH A - Verstehen jenseits einfacher Vorhersagen
Im Forschungsbereich A arbeiten wir an Algorithmen, die komplexe Strukturen und kausale Zusammenänge in Daten erkennen, um maschinelles Lernen besser in den wissenschaftlichen Erkenntnisprozess zu integrieren.
1
Enhancing Machine Learning of Lexical Semantics with Image Mining
- Projektleiter: Hendrik Lensch | Harald Baayen
- Projektmitarbeiter: Zohreh Ghaderi (Doktorandin)
Hassan Shahmohammadi (Doktorand)
Projektlaufzeit: Jan 2020 - Dez 2022
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
In current machine learning approaches to semantics, high-dimensional vector representations play a central role. These representations are derived from text corpora, using methods such as latent semantic analysis and word2vec. However, it is unlikely that our knowledge of what words mean are just a function of the distributional statistics of words' co-occurrences in texts. Our knowledge of entities and events in the world that are communicated with the help of words is part and parcel of words' meanings. Bruni et al. (2014) therefore started investigating whether high-dimensional vector representations can be constructed for images, with the goal of combining these vectors with text-based vectors to enhance prediction of human ratings of the semantic relatedness of words. Gains in prediction accuracy have been modest, however.
The aim of the research proposed here is to move this line of research forward by making use of more advanced methods in machine learning and computer vision.
2
Extracting Expertise from Tweets: Exploring the Boundary Conditions of Ambient Awareness
- Projektleiterinnen: Isabel Valera | Sonja Utz
- Projektmitarbeiter: Pablo Sánchez Martín (Doktorand)
Projektlaufzeit: Sept 2019 - Aug 2022
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Recently, social scientists have shown that the use social media, such as LinkedIn results in the awareness of who-knows-what. This is a process called ambient awareness and it is an important first step in successful knowledge exchange (Fulk & Yuan, 2013) with potential professional informational benefits, i.e., timely access to work-relevant information. Prior research on ambient awareness based on machine learning techniques has taken place in highly structured social networks such as Stack Overflow.
In this project, we aim to develop a probabilistic machine learning model based on latent variables and stochastic processes that allows us to study if, and to which extent, ambient awareness information can be extracted from less structured networks (e.g. Twitter) where a lot of challenges arise since the data is huge, heterogeneous and noisy. Besides, it is not clear how to disentangle expertise, social influence, and interest.
3
Extending Deep Kernel Approaches for Better Prediction and Understanding of ADME Phenotypes and Related Drug Response
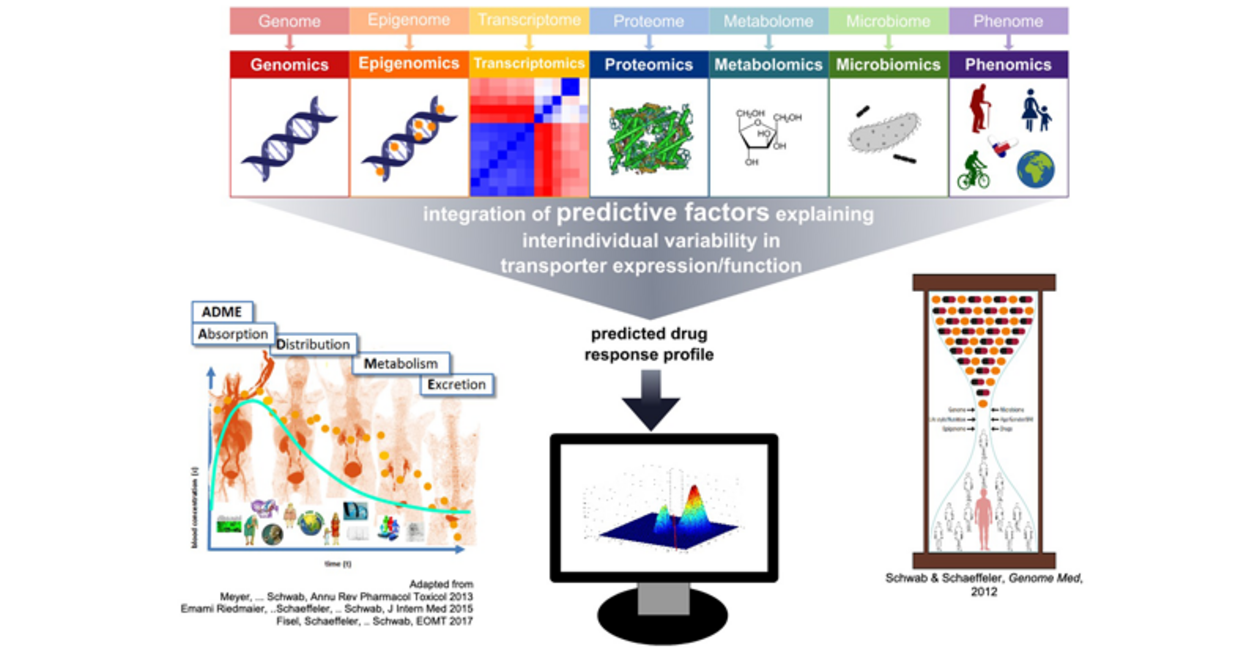{kind=link}
- Projektleiter: Nico Pfeifer |
Matthias Schwab - Projektmitarbeiter: Jonas Ditz (Doktorand)
Projektlaufzeit: März 2020 - Feb 2023
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Precision medicine is understood as a medical approach in which patients are stratified based on their disease subtype, risk, prognosis, or treatment response using specialized diagnostic tests. The impact of genetic variation in the up to 300 ADME genes (Absorption, Distribution, Metabolism, Excretion) on drug response is a substantial part of the concept of precision medicine, termed as pharmacogenomics (PGx). Meanwhile, major efforts are spent on implementing the PGx knowledge into clinical practice. PGx information is also part of labels of drugs used in various medical disciplines.
The heterogeneity in expression and function of ADME genes like CYP2D6 among individuals is determined by the interaction of genetic but also non-genetic factors, as well as epigenetic modifications, limiting the prediction of drug response exclusively based on genetic alteration. Of note, the significance of epigenetic regulation of gene expression in the context of drug response and ADME is just evolving as well as the consideration of the human metabolome.
Thus, a comprehensive approach of consideration of genetic, non-genetic, epigenetic and metabolomic factors for a more precise and valid prediction of ADME–dependent pharmacokinetic and pharmacodynamic processes is necessary. Recently, a strong dependency of precision medicine on computational solutions has been suggested but modern approaches from data science, specifically machine learning related to ADME processes and PGx has not been considered systematically so far. Very recently excellent reviews summarize the potential of machine learning as it relates to biological research and explore opportunities at the intersection of machine learning and network biology. In particular, deep neural networks have been already successfully used for prediction of drug response in treatment of cancer and other entities. Building neural architectures from sequence kernels has recently been introduced as a powerful technique to build state-of-the-art prediction methods. In this setting the kernels were based on n-gram similarities, but also approaches based on mismatch kernels that can account for gaps have recently been shown to outperform state-of-the-art methods.
The aim of this project is to extend these approaches to get further performance improvements and providing interpretable models. We will also evaluate, how to extend the methodology to allow for multi-view data. The ultimate goal of the application is to better predict drug response phenotypes taking into account particularly ADME targets which are substantially involved in pharmacokinetic/-dynamic processes as well as gaining a better understanding of the underlying mechanisms.
4
Applied Causal Inference in Social Sciences and Medicine
- Projektleiter: Dominik Papies | Philipp Berens
- Projektmitarbeiter: Jonathan Fuhr (Doktorand)
Projektlaufzeit: Mai 2020 - April 2023
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Empirical research in social sciences, including economics and business, as well as in biomedical research has traditionally been concerned primarily with the identification of causal effects; examples are: (1) What is the effect of schooling on wages? (2) What is the effect of a diet on longevity? (3) Does the introduction of a microfinance program lead to more economic growth? (4) What is the effect of a genomic variant on the propensity to develop heart disease? (5) What is the relation between a product’s price and demand?
In many of these research settings, experimental interventions are costly or infeasible; hence, researchers often have to rely on observational data, i.e., data in which they cannot actively change values of the explanatory variables of interest (X), but passively observe the values X being changed. This complicates the identification of causal effects. Traditionally, in the absence of experimental (i.e. interventional) data, these, and similar questions, have been addressed with statistical methods that rely on strong assumptions.
In machine learning, algorithms to perform causal inference under potentially less restrictive assumptions have recently been developed. These methods can be described as methods that allow researchers to either test causal hypotheses based on the literature or theoretical ideas, or to identify causal structures in the absence of such prior information (i.e., causal discovery).
The aims of this project are:
(1) Assemble a suite of curated data sets from social sciences, business / economics and medicine in which causal questions are of interest, e.g. evaluation of a dataset from the area of economics on the relation between prices and demand, or a dataset on the epidemiology of age-related macular degeneration.
(2) For the “use cases” from (1) in which machine learning for causal inference is promising, we will empirically assess the feasibility and value of applying recently proposed frameworks to identify causal structure and estimate (heterogeneous) causal effects.
(3) We will assess whether these methods allow researchers to solve problems that were difficult to solve before, contrast them to classic econometric or biometric approaches and identify which challenges are involved in applying such methods in practice.
(4) We will transfer the identifying assumptions (i.e., the assumptions that must be met in order to be able to interpret the coefficients of interests as causal) of the respective methods to the language and theories of the respective fields and explore and discuss their plausibility.
(5) We will derive recommendations of “best practice” that may guide researchers who are interested in applying modern causal inference algorithms in econometric or biometric analysis.
5
Short-to-Mid Scale Weather Forecasting with a Distributed, Recurrent CNN

- Projektleiter: Martin Butz | Hendrik Lensch |
Thomas Scholten - Projektmitarbeiter: Matthias Karlbauer (Doktorand)
Projektlaufzeit: März 2019 - Feb 2022
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Weather constitutes an extremely complex chaotic system whose dynamics depend on a large manifold of parameters. Some well-known parameters are air pressure, temperature, wind, humidity, or precipitation. They are typically used by numerical physical simulations to generate weather forecasts. More sophisticated models combine these parameters with geographical information. Due to many additional, subtler interactions with geographical and environmental properties, including soil properties and current vegetation, many countries have created their own, specialized weather model. Moreover, a Weather Research and Forecasting Model (WRF) is widely used by scientists. All these models depend on extremely powerful computer hardware and solve complex systems of partially differential equations.
Despite this best effort, low-to-mid scale weather forecasting in the range of minutes up to days still remains somewhat mediocre. Particularly on the regional, ten-minute scale, forecasts about upcoming storms and rain are often unsatisfactory. The reason is that there are potentially thousands of additional, partly unknown local parameters, including geographical and soil properties, that influence local weather development. It remains unclear which additional parameters should be included at which granularity and resolution and how such additions should be optimally integrated into the existing physics-based models. Machine learning techniques offer an alternative. By now, a large quantity of historical weather data is available, which allows the training of (deep) artificial neural networks (ANNs).
The aim of this project is to study the inclusion of progressively more complex and fine-granular local properties, including, e.g., soil and terrain properties. Our intention is to develop a superior weather forecasting architecture, and contribute to the question which local properties at which temporal and spatial resolution and precision should be considered for optimizing weather forecasting systems.
First results of the project are presented on Youtube, presenting a video on the paper by M. Karlbauer, ... H.P.A. Lensch, T. Scholten, ..., M.V. Butz: A Distributed Neural Network Architecture for Robust Non-Linear Spatio-Temporal Prediction.
6
Analytic classical density fuctionals from an equation learning network
-
Projektleiter: Georg Martius | Martin Oettel
-
Projektmitarbeiter: Alessandro Simon (Doktorand)
Projektlaufzeit: Okt 2020 - Sept 2023
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Computing densities of molecules in a system with external potentials is a challenging and important problem which can be solved brute-force using molecular simulations or in a more efficient manner using classical density functional theory. There is both a theoretical interest in understanding principles behind underlying density functionals for complex fluids, but also a strong motivation from one overarching practical question: Precise information on the solvation of pharmaceutically relevant biomacromolecules is still a bottleneck for drug design in terms of evaluation time in explicit simulations.
The present project should be seen as a necessary intermediate step towards exact and fast density functionals for water fitted for that task. More specifically, we want to construct a functional equation learning network for patchy particles in 3D, trained on suitable simulation data. In their pair interaction potentials, patchy particles with their directional attractions represent one of the archetypically difficult cases for density functional theory and therefore we anticipate novel insights for the art of density functional construction through the application of machine learning methods.
FORSCHUNGSBEREICH B - Mit Ungenauigkeit umgehen lernen
In Forschungsbereich B erforschen wir Methoden, um Unsicherheiten in datengetriebenen wissenschaftlichen Modellen und Algorithmen quantifizieren und weiterverarbeiten zu können.
1
Visualizing Uncertainty from Data, Model and Algorithm in Large-Scale Omics Data
- Projektleiter: Kay Nieselt | Philipp Hennig
- Projektmitarbeiter: Susanne Zabel (Doktorandin)
Projektlaufzeit: Feb 2019 - Jan 2022
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
During the last 10 years, the biomedical domain has become a data-driven one. Making sense of data is an increasingly important task, driving the need for systems that enable people to analyze and understand data.
Deep sequencing and other high-throughput methods measure a large number of molecular parameters in a single experiment. The measured parameters include genome sequences, RNA and protein expression, and many more. Each such kind of data is termed ‘omics’ (e.g. genomics, transcriptomics, proteomics, respectively). A common instrument to make such omics data sets accessible are dimensionality reduction techniques, such as principal component analysis (PCA), multi-dimensional scaling (MDS) or t-Distributed Stochastic Neighbor Embedding (t-SNE). These can provide an approximate low-dimensional embedding of the given data set, and, as a special case, a planar map to visualize the data’s neighborhood structure. Although PCA, MDS or t-SNE are neither the only, nor the most appropriate methods for dimensionality reduction in general, they are the de facto standard in bioinformatics, in particular in omics studies. Their popularity is primarily founded in their algorithmic simplicity and they are easily accessible to the domain scientist. However, when details of such a dimensionality reduction map are then interpreted scientifically, they are actually not that simple after all. Since these algorithms are constructed from finite data sets, they are not always stable to even minor imprecisions in the data, and their sensitivity can vary from one data point to another, potentially giving undue weight to a small set of “crucial” data. Although many problems with these models have been pointed out in the past, and partially addressed with methods like independent component analysis (ICA), factor analysis, robust PCA, etc., the difference between these methods for a particular omics dataset are not always evident (in particular not visually evident) to the scientist conducting and interpreting the analysis.
The aim of this study is to develop an interactive web-based visual analytics tool that empowers biomedical and other researchers with minimal mathematical background to visually and quantitatively investigate uncertainty arising from data, model and algorithm in dimensionality reductions.
2
Modelling Behavioral Responses to Emotional Cues in Sports – A Bayesian Approach
-
Projektleiter: Augustin Kelava |
Tim Pawlowski -
Projektmitarbeiter: Lukas Fischer (Doktorand)
Michael Nagel (Doktorand)
Projektlaufzeit: Jan 2021 - Juni 2022
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
In this project, we intend to complement the recently growing literature (see for instance Card & Dahl, 2011, Quarterly Journal of Economics or Ge, 2018, Journal of Economic Behaviour & Organization) empirically testing Koszegi and Rabin’s (2006, Quarterly Journal of Economics) theoretical prediction, that utility from deviations between (rationally) expected references points and actual outcomes (i.e. gain-loss utility) influences behavior under uncertainty. In contrast to many other studies, frequently struggling in identifying appropriate reference points when testing for field evidence of reference-dependent behavior, these papers make use of a setting, where (average) reference points can be directly inferred from the betting market, i.e. professional sports.
Aim of this project is to contribute to this literature in four ways: First, this is the first project exploring in a real life setting the link between reference points and alcohol use: a ‘phenomenon’, which is deeply rooted in society, widely recognized as a leading risk factor for death and disability and a major contributor to criminal behavior such as family violence. Second, our particular setting in combination with the available intensive longitudinal multilevel data allows us to further disentangle the cause and consequences of reference point behavior, e.g. by testing the relevance of emotional salience and the degree of emotional ‘involvement’ as a fan of either the home or away team. Third, studies testing psychological theories of drinking and alcoholism have historically relied on lab experiments in combination with self-reported survey data. While manipulations of emotions are generally difficult to execute and control in the lab, self-reported survey data on alcohol use are subject to recall and/or social desirability biases. As such, our setting might offer for the first time some reliable field evidence for these theories. Fourth, our specific data structure is expected to require a departure from standard specifications using intensive longitudinal multilevel time series techniques (e.g., Asparouhov, Hamaker, & Muthen, 2018, Structural Equation Modeling). However, such models need to consider sparsity and application/development of new regularization techniques (such as Bayesian adaptive lasso priors in statistical learning). As such, a methodological focus is put on the development and application of Bayesian time series models that blend properties of multilevel models, latent variable models, and generalized additive models.
_________________________________________________________________________________________________________
Weitere Informationen: Data Science and Sports Lab
_________________________________________________________________________________________________________
Den Forschungsstand zu diesem Projekt fasste Tim Pawlowski in einem Buchkapitel zusammen:
Reference point behavior and sports (preprint)
(in: Hannah Altman, Morris Altman, Benno Torgler, eds.
Behavioural Sports Economics. New York: Routledge (forthcoming 2021))
3
Understanding Quantum Effects in Neural Network Models through ML
-
Projektleiter: Sabine Andergassen |
Igor Lesanovsky -
Mentor: Georg Martius
- Projektmitarbeiter: Paolo Mazza (Postdoc)
Projektlaufzeit: April 2020 - März 2022
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
It is widely believed that computational processes can benefit by exploiting the properties of quantum mechanics. In particular, it has been shown that quantum algorithms can outperform their classical counterparts. An important and timely question is whether it is possible to take advantage of quantum effects in Neural Network computing. The problem is a conceptual one: the dynamics of closed quantum systems is governed by deterministic temporal evolution equations, whereas Neural Networks are always described by dissipative dynamical equations. This represents an obstacle for a straightforward generalization of Neural Network computing to the quantum domain.
The aim of this project is to investigate the role of quantum effects in models of Neural Networks which are formed by interacting spin systems. To this end, we will employ numerical techniques based on machine learning to shed light on the dynamics and stationary states of these many-body systems. Our research will deliver insights concerning the usefulness and possible advantages of quantum effects in Neural Network applications. Moreover, it will advance state-of-the-art machine learning approaches for tackling pressing questions in the domain of quantum many body physics, ranging from condensed matter and ultra-cold atoms to quantum computing devices.
4
Inductive bias of learning algorithms in climate science
-
Projektleiter: Ulrike von Luxburg | Bedartha Goswami
- Projektmitarbeiter: Moritz Haas (Doktorand)
Projektlaufzeit: Mai 2021 - April 2024
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
All machine learning algorithms necessarily have an inductive bias. In this project, we aim to study this inductive bias in a specific scientific domain, namely climate science. Here, climate networks help detect long-range interrelations and to study spatial patterns based on temporal behaviour. They have been used to predict the El Nino Southern Oscillation and the Indian monsoon.
In our project, we aim to systematically specify the inductive bias of the construction climate networks and the statistical tests based on their randomized versions. Ultimately, we hope to be able to quantify the extent of influence of inductive biases on the final inferences made using climate networks.
FORSCHUNGSBEREICH C - Schnittstelle zwischen Algorithmen und Wissenschaftlern
Im Forschungsbereich C entwickeln wir Techniken, die es Wissenschaftlerinnen und Wissenschaftlern aus verschiedenen Disziplinen ermöglichen, die einzelnen Schritte des maschinellen Lernens besser zu verstehen und sie interpretierbar und kontrollierbar zu machen.
1
Interpretable Spatial Machine Learning for Environmental Modelling
-
Projektleiter: Philipp Hennig |
Thomas Scholten -
Projektmitarbeiter: Thomas Gläßle (Doktorand)
Kerstin Rau (Doktorandin)
Projektlaufzeit: März 2020 - Feb 2023
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Over the past two decades the research area of pedometrics evolved as an overlap between soil science and machine learning (ML). Although first approaches date back to the 1990th, a stronger focus on integrating ML approaches to generate soil maps and to extract pedological knowledge is visible within the past 10 years. Approaches mainly comprise regression and supervised classification, analysis of feature importance, spatial data mining, validation, feature construction, the analysis of uncertainty and sampling design. The main focus is on spatial modelling, i.e. generating soil property maps. This has become of ample importance against the background of climate change, food security, biodiversity loss, environmental pollution, etc., were soils as the uppermost part of the Earth’s surface link bio-, hydro-, atmo-, and lithosphere and act as filter and transformer.
In this project we aim at
- developing, integrating and comparing feature construction approaches which allow to integrate spatial dependency and context in ML approaches.
- developing measures of feature and scale importance and interactions to extract knowledge on environmental genesis.
- implementing new (deep) learning and Gaussian processes solutions for specific data scenarios.
- developing measures and tools for uncertainty analysis and propagation with respect to noisy feature construction as well as understanding soil formation and guiding sampling design to make models more robust.
2
Human-Robot Interface with Eye-Tracking
- Projektleiter: Enkelejda Kasneci | Andreas Zell
- Projektmitarbeiter: Daniel Weber (Doktorand)
Projektlaufzeit: Mai 2019 - April 2022
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
One of the greatest challenges for model development in state-of-the-art machine learning is how to obtain enough labelled training data with high-quality labels. For some applications, like single image analysis of individual objects of a limited number of categories, there exist large benchmark data sets, like MNIST or ILSVRC. Most of these, however, are available for 2D images, with some smaller 3D point cloud data sets which have been made available recently. In the context of autonomous driving, most large car manufacturers or companies like Google and Uber have established their own large image and video data datasets, in most cases based on Amazon Mechanical Turk or other service companies in countries with cheap human labor. In the context of service robots operating in office environments or in warehouses, there are no datasets which are tailored to the environment, encompass all relevant object classes, do not contain irrelevant objects and are fully labelled. However, such datasets are exactly what is required to make mobile robots not only more capable with regard to the tasks that they have to accomplish, but also more user-friendly. More specifically, for a fluent and intelligent interaction with such robots, the systems have to learn to recognize most objects in their environment.
The aim of this project is to investigate how mobile robots can learn most of the objects in their environment very efficiently by interacting with humans who teach them. To achieve this goal, the research groups of Andreas Zell, which specializes on deep learning algorithms for mobile robots, and Enkelejda Kasneci, specializing on eye-tracking and trainable human-machine interfaces will collaborate to establish a system, by which a human can effectively train mobile robots.
3
Machine Learning Approaches for Psychophysics with Ordinal Comparisons
- Projektleiter: Felix Wichmann |
Ulrike von Luxburg - Projektmitarbeiter: David Künstle (Doktorand)
Projektlaufzeit: März 2020 - Feb 2023
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Much of the progress in experimental psychology and cognitive science over the last 150 years stems from well-controlled measurements of human behavior. Precise stimulus control has been considered the “first commandment of psychophysics”, and the quantitative study of human behavior has preferred accuracy over quick data acquisition.
In this project we investigate more intuitive and robust ways of presenting stimuli and measuring participants’ responses in form of triplet comparisons. Rather than attempting accurate quantitative measurements of a particular phenomenon, our comparison-based approach aims for qualitative observations of the form “Stimulus X is more similar to stimulus Y than to stimulus Z”. The obvious potential of such an approach is that the statements may be less dependent on the fine details of the experimental setup, and that the issue of scaling answers across many participants becomes easier. To make efficient use of triplet comparisons, we resort to the field of machine learning. The evaluation of triplet-based data has been an active field of research in the field of machine learning, and a number of fast and powerful algorithms have been developed during the last couple of years. In this project we extend these algorithms to the field of psychophyics and derive new, machine-learning based pipelines for the field of experimental psychology.
4
Counterfactual Explanations of Decisions of Deep Neural Networks with Applications in Medical Diagnostics
-
Projektleiter: Matthias Hein | Philipp Berens
-
Projektmitarbeiter: N.N. (Doktorand)
N.N. (Assistenzärztin/arzt)
Projektlaufzeit: 2020 - 2023
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Currently employed neural networks for classification are susceptible to adversarial examples and thus the confidence of the classifier (maximal probability over the classes) is not a reliable indicator if one is currently on the "data manifold’’ or not. Moreover, neural networks produce over-confident predictions far away from the training data which can be critical for a medical diagnosis system if the classifier does not flag reliably unknown images which potentially require human inspection (Hein et al., 2019). Both issues are a problem for counterfactual explanations if we want to use the classifier confidence as an indicator of the "data manifold’’.
This project pursues the idea of improving the explainability of deep neural network (DNN) predictions by generating counterfactual explanations: These are specifically generated artificial images that show what a minimal change of the input image must look like for the DNN's decision to change. In contrast to adversarial examples, the counterfactual explanations should have a high probability regarding the data generating distribution, i.e. move on the "data manifold''. We will apply these techniques in a medical context to existing networks for the diagnosis of diabetic retinopathy or respectively re-train them using the techniques developed in the project. In a medical setting, good explanations play a crucial role in meeting the challenges incurred by the application of ML systems (Grote and Berens, 2019).
Specifically, we will
1. Develop new techniques for training neural networks so that the confidence of the classifier is a reliable indicator if one is on or off the data manifold, that is adversarial samples or out-of-distribution samples have both low confidence. We will compare them to existing approaches for uncertainty quantification in DNNs based on dropout or test-time data augmentation.
2. Develop new optimization techniques for visual counterfactual explanations to create minimal changes of the image in high-confidence regions of the classifier so that the decision changes.
3. Apply and evaluate the setup in a diagnostic setting. The experience gathered in this evaluation is likely to provide new modelling constraints for the visual counterfactual explanations.