Stereo matching is one of the popular approaches for depth estimation using binocular vision. In essence, by finding the matching points between a pair of rectified left and right images, one can compute the disparity (displacement) between these points and easily infer the depth. This passive strategy is in contrast to other techniques, which adopt lasers or light sources to actively measure the depth, and thus, it can handle more challenging scenarios.
Stereo vision has benefited from deep neural networks, bringing in more accurate binocular depth estimations. In particular, the end-to-end networks, which process the whole pipeline in one network, have yielded a substantial increase in the disparity estimation accuracy compared to classical methods. However, on the other side of the coin, these networks have a huge computational complexity, which often hinders them to be executed even on a moderate GPU.
As such, designing light-weight deep networks is becoming one of the most active areas of research in the computer vision community. Likewise, this is essential for deep stereo matching networks, especially if these networks need to be utilized in devices with memory constraints or in fast runtime scenarios. Accordingly, in this project, we mainly investigate methods to lower the computational burden of these networks, while maintaining the high accuracy of disparity maps.
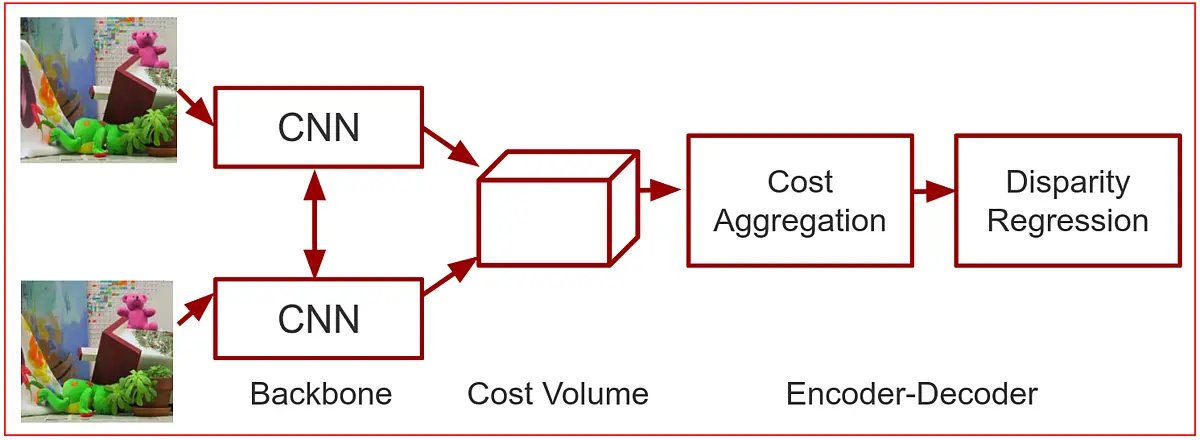
{kind=link}