Laufendes Projekt
Dialektgeographie und Dialektometrie von Ladakh (UT Ladakh, Indien) (II/2026-I/2029)
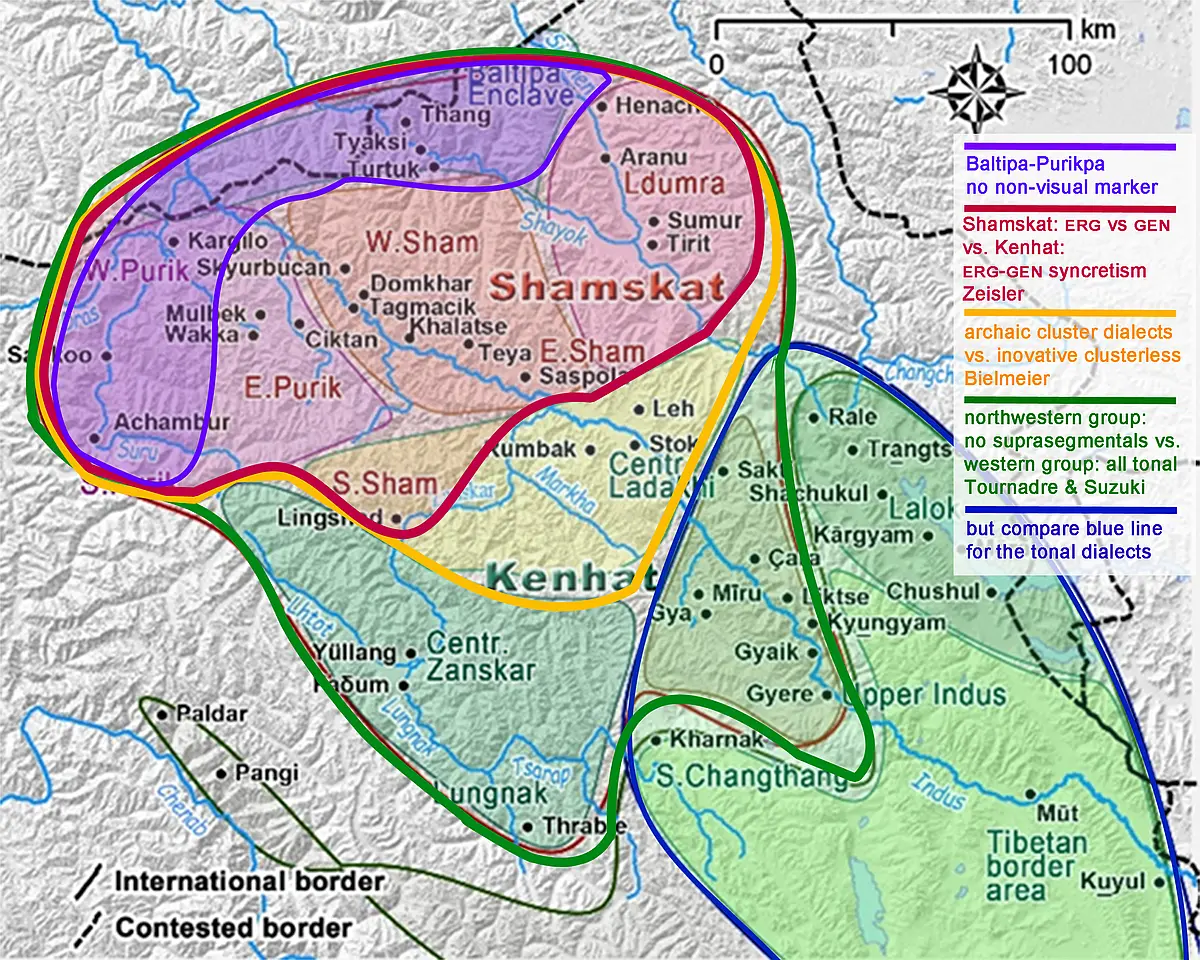
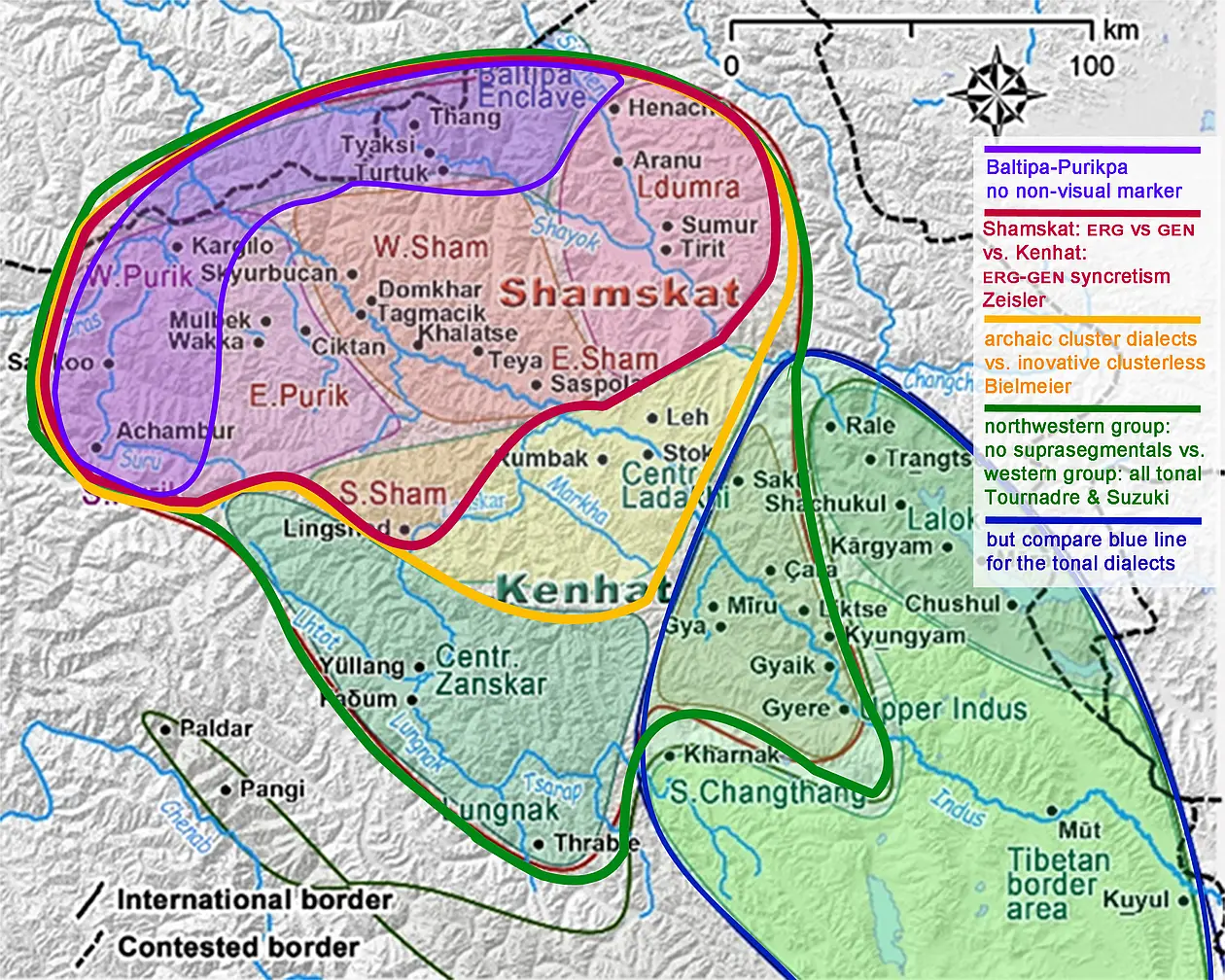
The Ladakhi dialects form three greater dialect groups or even languages: 1. Shamskat ‘the lower language’: the dialects of Lower Ladakh, Ldumra (a.k.a. Nubra), and East-Purik. Most distinctive for this group is that transitive agent and possessor are distinguished morphologically. 2. Kenhat ‘the upper language’: the dialects of Upper Ladakh and Zanskar, displaying ergative-genitive syncretism. 3. The Baltipa-Purikpa group as a Shamskat subgroup, lacking a special marker for non-visual perceptions with signifcant differences in the lexicon. Alternative binary classifications are a differentiation between ‘archaic’ dialects that show initial consonant clusters and ‘innovative’ dialects that lack these clusters or a differentiation between a ‘northwestern’ group of dialects without suprasegmental features or tone and a ‘western’ group of tonal dialects, albeit the ±tonal divide crosscuts both groups. The classificatory boundaries vary thus significantly, but none of them is based on statistics, see graphi below. The Project aims to close this lack of statistical data by using a set of more than 100 morphological items and a set of more than 600 everyday vocabulary items.
Computational dialectometry focuses on sound correspondences in cognate word forms. These features are aggregated to compute pairwise distances between dialects. In a subsequent step, these distances are analysed through clustering, multidimensional scaling, and spatial regression via generalised additive models. The results often coincide with traditional isogloss boundaries but are also capable of revealing patterns not readily accessible through qualitative methods. Phylogenetic linguistics focuses on cognate sets, and thus quantifies lexical replacement. Moreover, phylogenetic approaches assume that linguistic diversity arises through repeated splits of language communities, resulting in a branching genealogical structure. The primary goal is to infer the tree—or set of trees—that best explains the observed distribution of features under probabilistic models of evolution. While these traditions are often pursued separately, they can be fruitfully integrated. Features based on automatically inferred sound correspondences are a viable alternative to manually annotated cognate sets in phylogenetic inference. Newer statistical methods factor out the effects of contact when inferring phylogenetic relationships, thus enabling a more nuanced view of linguistic diversification in contact zones such as Ladakh.
With respect to such computerised language measurements and tree modelling, many linguists hold that differences in phonology, lexicon, and morphology are equally important or that the differences in the lexicon, which are naturally higher in number than the differences in morphology, weigh more than the latter. Nevertheless, it is also generally known that innovations in phonology and in the lexicon develop and spread faster than grammatical features. The lexicon is particularly susceptible to influences from prestige or dominant languages or dialects. We thus also want to show how different approaches, e.g., using only the lexical data, only the morphological data, both sets together, as well as different weighing might lead to different results. All results shall be discussed in view of the speakers’ own assessments, geography, climate, and ethno-historical facts to figure out the more convincing ones.
Abgeschlossene Projekte / Completed projects
Evidentialität, epistemische Modalität und Sprecherhaltung im Ladakischen - Modalität und die Semantik-Pragmatik-Grammatik-Schnittstelle / Evidentiality, epistemic modality, and speaker attitude in Ladakhi - Modality and the interface for semantics, pragmatics, and grammar (II/2016-I/2019 and, after the corona break VI/2022-V2024)
Das Ladakische ist eine tibetische Sprache, die in Nordindien (Jammu & Kashmir) gesprochen wird. Die tibetischen Sprachen und einige weitere tibeto-burmanische Sprachen haben ein besonderes System evidentieller Markierung mittels Hilfsverben, das in der Sprachtypologie bislang nicht vollständig berücksichtigt wird, da es offenbar nicht ausreichend analysiert ist. Im allgemeinen wird zwischen direkten und indirekten Wissensquellen unterschieden. Erstere erfaßt die Selbstwahrnehmung des Sprechers in bezug auf eigene Handlungen und Fremdsituationen, die er unmittelbar wahrnimmt. Aussagen aus diesem Bereich kommt automatisch ein hoher Wahrheitsgehalt zu. Zu den indirekten Wissensquellen zählen Hörensagen und Schlußfolgerung. Beide können, müssen aber nicht mit einem geringeren Wahrheitsgehalt assoziert werden. In den tibetischen Sprachen liegt der Hauptunterschied jedoch zwischen autoritativ bekräftigbaren Situationen, einschließlich eigener Handlungen, und bloß beobachteten Situationen, für die sich der Sprecher keine Autorität anmaßen will, kann oder darf. Das System ist sehr flexibel und die Auswahl der Hilfsverben ist stark pragmatisch kondizioniert. Ziel des Projektes ist die adäquate Beschreibung des komplexen grammatischen Systems evidentieller und im weitesten Sinne epistemischer Markierungen in den ladakischen Dialekten aufgrund einer qualitativen und, so weit möglich, quantitativen Untersuchung. Um 4Dialektvarianten von individuellem Sprechverhalten abzugrenzen, sollen möglichst viele Sprecher aus möglichst vielen Dialekten systematisch befragt werden. Insgesamt trägt das Projekt zur Erforschung der Semantik-Pragmatik-Grammatik-Schnittstelle im Bereich Modalität bei. Es dient der genaueren Unterscheidung von Evidentialität und epistemischer Modalität einerseits sowie der Abgrenzung von Sprecherhaltung (speaker attitude, stance) als eigenständiger Perspektivierung oder Profilierung von Aussagen andererseits und fördert das Verständnis von Evidentialität und Sprecherhaltung als grammatische Kategorien. Dies erlaubt auch ein besseres Verständnis entsprechender modale Strategien, d.h., sekundärer Verwendungen modaler Verben und Partikeln. Gleichzeitig dient das Projekt der Dokumentation einer langfristig gefährdeten und bisher noch wenig erforschten Sprache.
Summary:
Ladakhi is a Tibetic language, spoken in North India (Jammu & Kashmir). It consists of two major dialect groups, which differ considerably in their grammar. With respect to the object of investigation, however, they behave rather similar. The Tibetic languages and a few other Tibeto-Burman languages have a particular system of evidential marking through auxiliary verbs, which is not fully taken into account in the cross-linguistic discussion, most probably, because it is not yet fully analysed. Generally, one discriminates between direct and indirect sources of knowledge. The former consist of self-awareness with respect to one's own actions and the immediate or direct observation of situations of others. Statements concerning this domain automatically have a high truthvalue. Indirect knowledge consists of hearsay and inferences. Both may, but need not, go along with connotations of a decreased truthvalue. In the Tibetic languages, however, the main opposition is between situations the speaker can assert with authority and merely observed situations, for which the speaker cannot, does not want to, or is not allowed to assume authority. The system is highly flexible, and the choice of auxiliaries is pragmatically conditioned. The project aims at the adequate description of the complex grammatical system of evidential and in the widest sense epistemic markers used in the Ladakhi dialects on the base of a qualitative and, as far as possible, quantitative investigation. In order to delimit dialect variation from individual language use, as many speakers from as many dialects as possible should be interviewed systematically. The project will contribute to research into the semantic, pragmatic, and grammatical interface in the domain of modality. It will lead to a more precise differentiation between evidentiality and epistemic modality, and will further establish speaker attitude (or stance) as an independent perspectivisation or profiling of statements. It will thus contribute to a better understanding of evidentiality and speaker attitude as grammatical categories as well as a better understanding of evidential and attitudinal strategies, that is, secondary usages of modal verbs and particles. At the same time, the project aims at the documentation of a, in the long run, endangered and until now not yet well-studied language.
Verbsemantik und Argumentstruktur, Valenzwörterbuch der ladakischen Verben (IV/2010-III/2013 u. I/2014-VI/2014)
Mitarbeiter: Fabian Kliebhan (Softwareentwicklung), Rebecca Norman (Ladakh, beratend)
Mitarbeiter im Feld (Informanten):
2010: Tshomo Menggyur, Tshering Dolkar, Jigmet Angchuk, Sonam Rinchen
2011: Jigmet Yangdrol, Jigmet Angchuk
2012: Tshomo Menggyur, Tshering Dolkar, Jigmet Angchuk
Zusätzlicher Aufenthalt 2013: Tshomo Menggyur, Tshering Tshomo, Jigmet Angchuk, Sonam Rinchen
Zusätzlicher Aufenthalt 2014: Tshering Tshomo, Tshomo Menggyur, Tshering Dolkar
Zusätzlicher Aufenthalt 2015: Jigmet Yangdol, Tshering Tshomo, Tshomo Menggyur, Tshering Dolkar
Projektskizze
Ziel dieses im April 2010 begonnenen DFG-Projektes ist die Beschreibung der Verbvalenz sowie der Kasusrahmen und deren Bezug zur Verbsemantik für jeweils einen repräsentativen Dialekt aus beiden Gruppen sowie die Publikation eines entsprechenden Valenzwörterbuches. Kasusrahmen (oder Satzbaupläne) spezifizieren die Anzahl und Art der Argumente (auch Aktanten oder Partizipanten) eines Verbs, die Notwendigkeit ihres kontextunabhängigen Auftretens, die bevorzugte Position im Satz, die jeweiligen Kasus sowie mögliche Alternationen in Stellung und/oder Kasusmarkierung. Die Möglichkeit derartiger Alternationen, deren semantische oder pragmatische Implikationen sowie die Dokumentation von Kollokationen bilden besondere Schwerpunkte.
Zum Wörterbuch (eingeschränkte Betaversion)

{kind=link}
{kind=link}
Semantische Rollen, Kasusrelationen und satzübergreifende Referenz im Tibetischen (I/2002-XII/2008)
Im Rahmen des SFB 441 'Linguistische Datenstrukturen: Theoretische und empirische Grundlagen der Grammatikforschung'
Im Mittelpunkt des Projekts stand die Formulierung von Regeln für die Identifikation von Antezedentien leerer Argumente im Tibetischen. Dabei war im einzelnen auf die Verbsemantik einzugehen, d.h. auf die Argument- und Ereignisstruktur der Verben und auf die Einteilung der Verben nach ihrer Aktorenart ([±Kontrolle]). Die Perspektive des Projekts ist primär eine empirische und deskriptive, sekundär eine allgemein vergleichende und theoretische. Das Projekt basierte auf der Auswertung der zu erstellenden Textkorpora schriftlicher und mündlicher Erzählliteratur verschiedener Epochen, der Auswertung der durch Befragung und Elizitation gewonnen Daten sowie auf der einheimischen grammatischen Literatur. Durch die verschiedenen Datenklassen (Korpusdaten, Beurteilungsdaten, Elizitationsdaten, deskriptive historische und rezente Daten sowie normative Daten tibetischer Grammatiker) und durch die Zusammenführung verschiedener methodischer Ansätze (Philologie, Linguistik, historische Sprachwissenschaft und einheimische tibetische Grammatik) trug das Projekt zur Leitfrage des SFBs bei: der Klärung des Verhältnisses von Theorie und Empirie im Hinblick auf unterschiedliche Datentypen und deren Bewertung.
Zu den Korpora
OTC: Alttibetische Chronik, Kapitel I (ca. 9. Jh.)
TVP: Die Tibetische Version des Papageienbuchs (ca. 15. Jh.)
LLV: Gšamyulna bšadpaḥi Kesargyi sgruŋs bžugs. A Lower Ladakhi Version of the Kesar Saga (um 1900 gesammelt)
(siehe auch Metadaten, Dokumentation & Definitionen, Aufbau der Präsentation
auf den alten Projektseiten (zum Teil weiter aktualisiert)
alternativ: Metadaten, Dokumentation & Definitionen, Aufbau der Präsentation
auf den archivierten Seiten (Stand 2009))