Zielsetzung
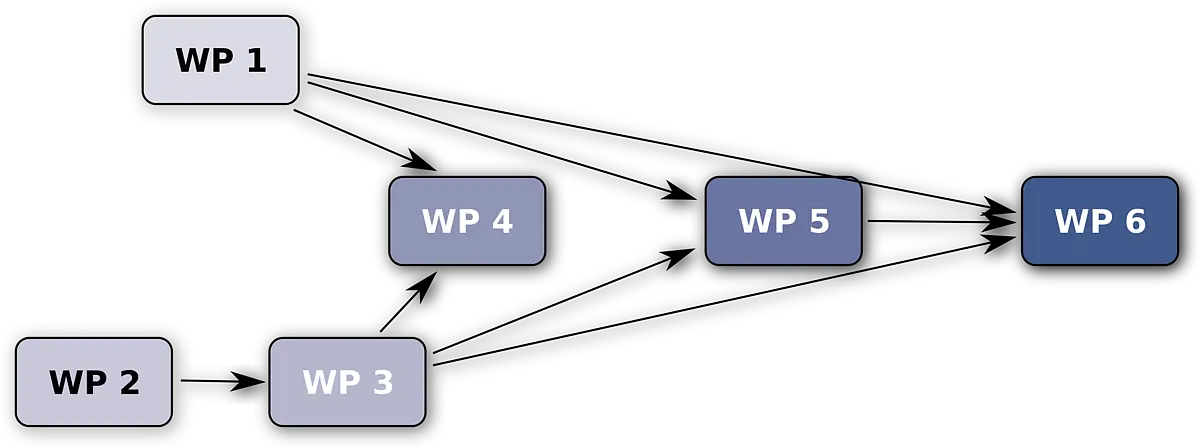
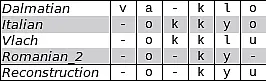
Arbeitspaket 1: Lexikalische Rekonstruktion
Arbeitspaket 2: Hierarchische pyhlogenetische Markov und multinominal Modelle
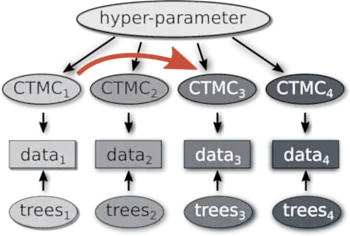
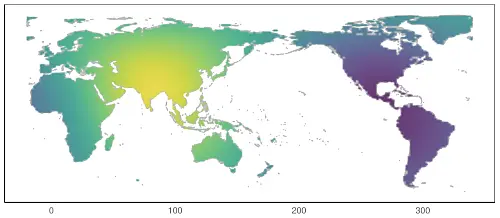
Arbeitspaket 3: Sprachkontakt und räumliche Zufallseffekte
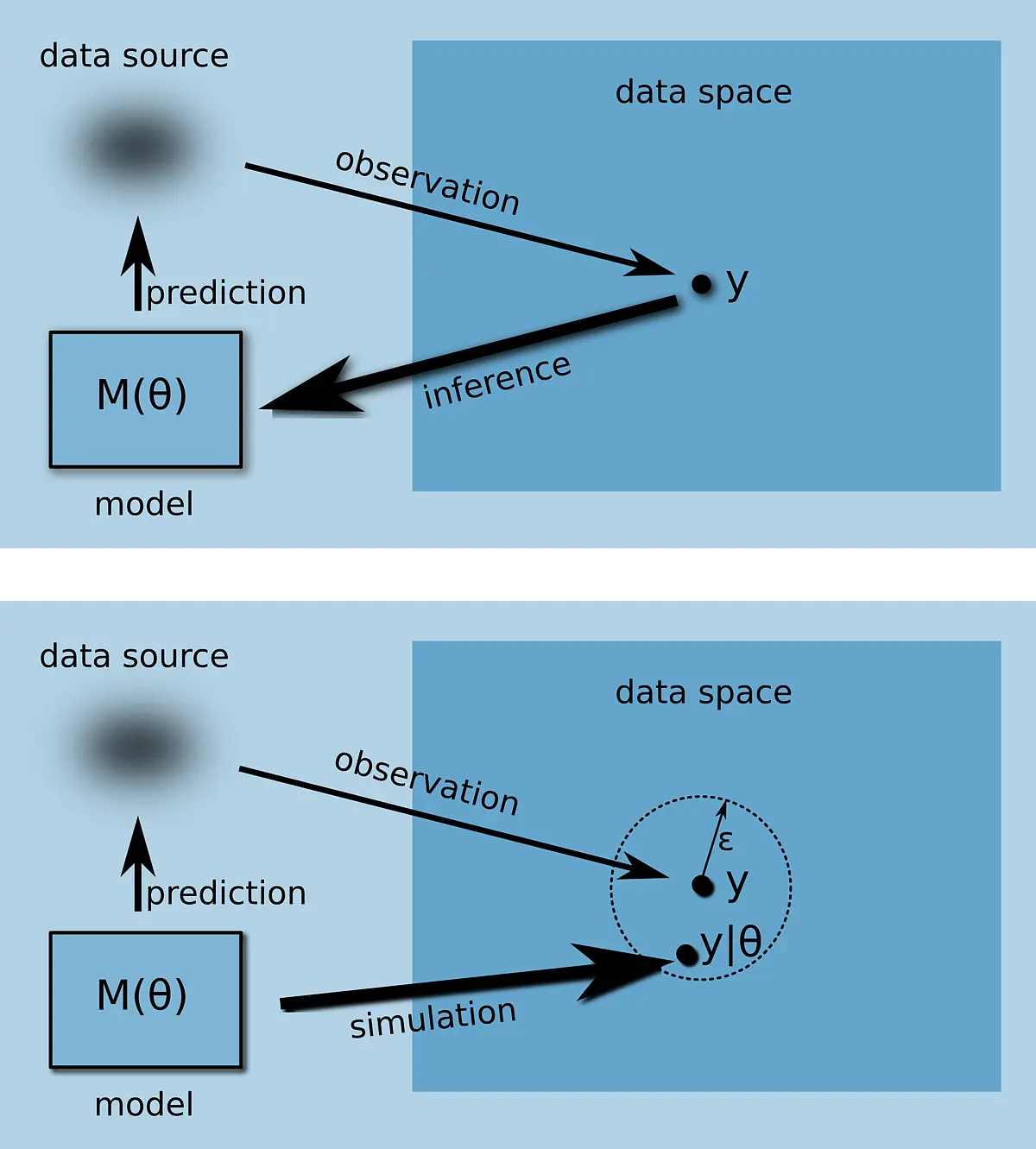
Arbeitspaket 4: Approximative Bayessche Berechnung und agentenbasierte Simulation
Arbeitspaket 5: Kausale Inferenz

Arbeitspaket 6: Softwarebibliothek
