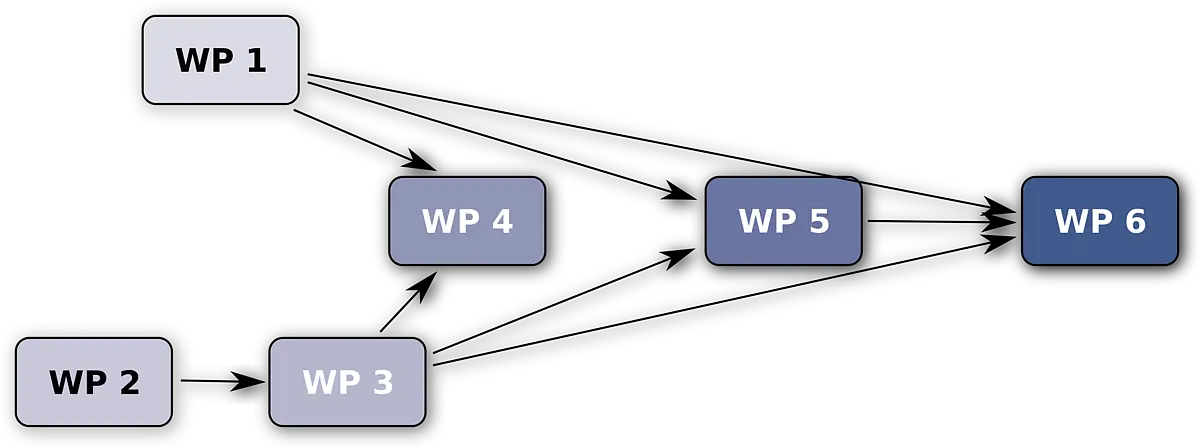
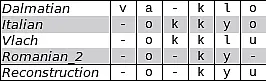
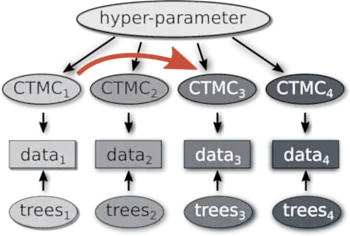
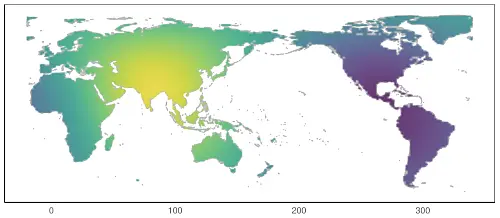
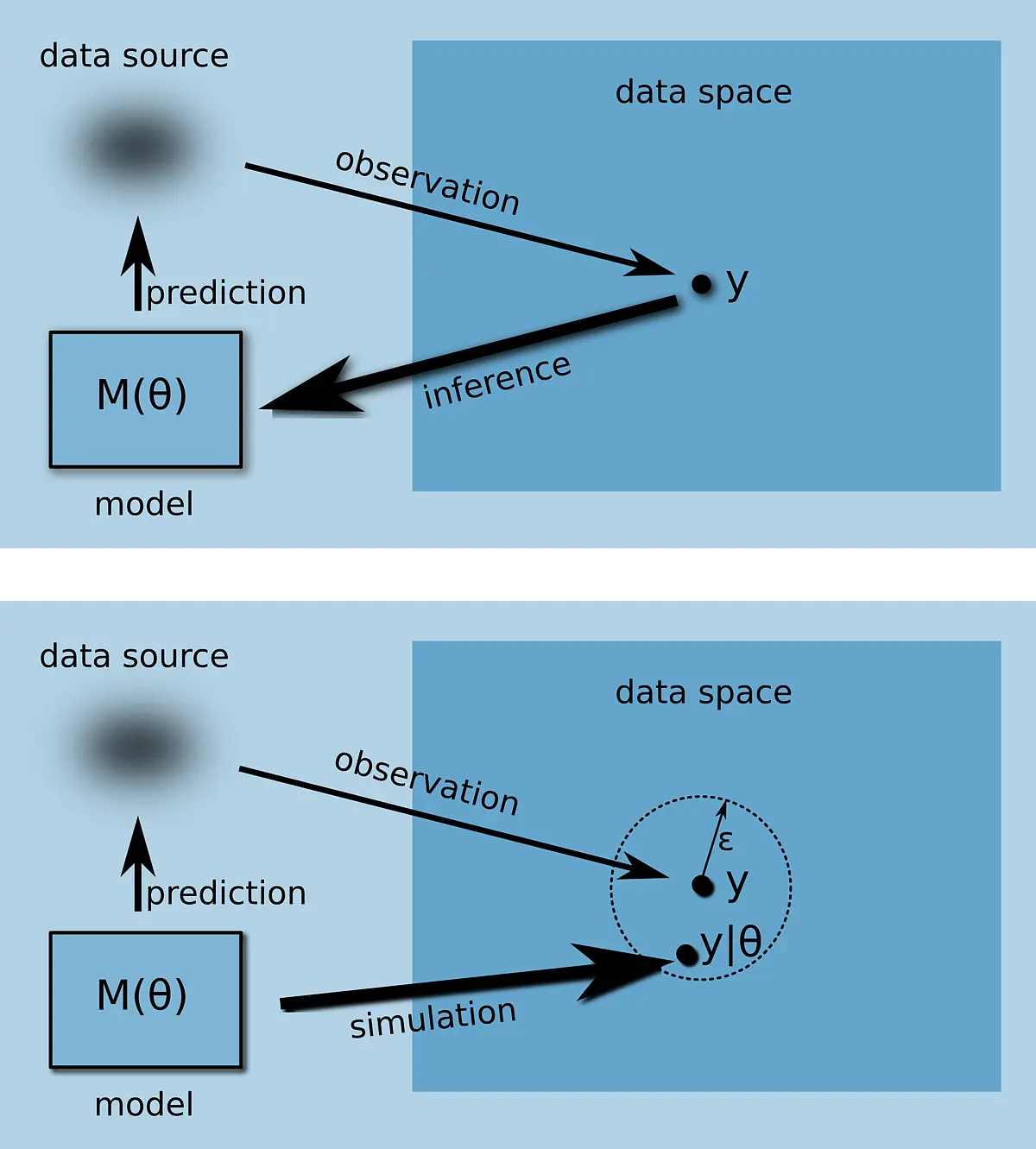
Based on results from computational historical linguistics and statistical typology, CrossLingferences goal is to establish a probabilistic framework to analyze change and diversification processes in language. This enables the investigation of issues located at the interface of historical linguistics and typology. On the one hand, existing methods and algorithms should be adapted and on the other hand novel approaches should be developed to answer these questions. Special attention will be paid to hierarchical Bayesian methods.