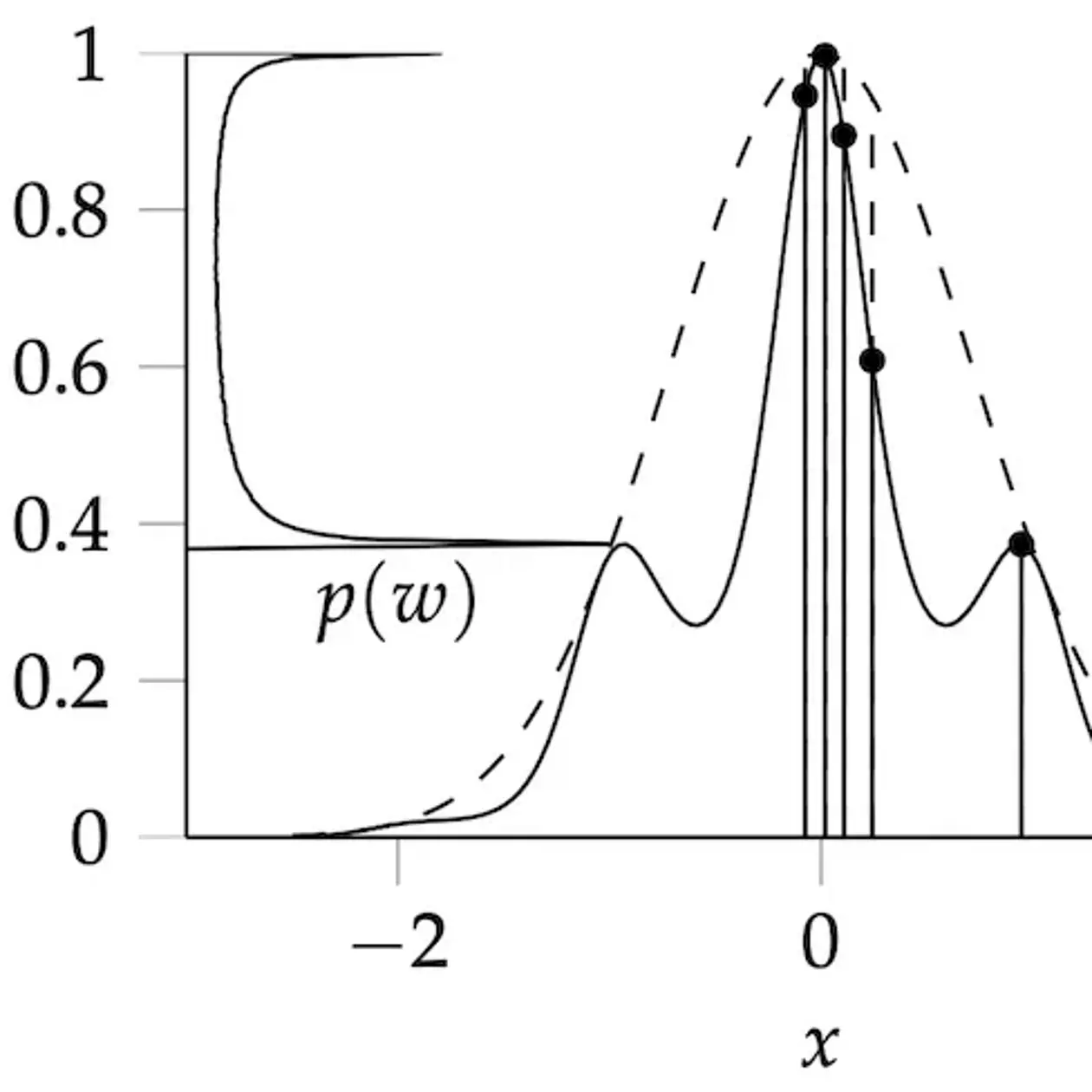
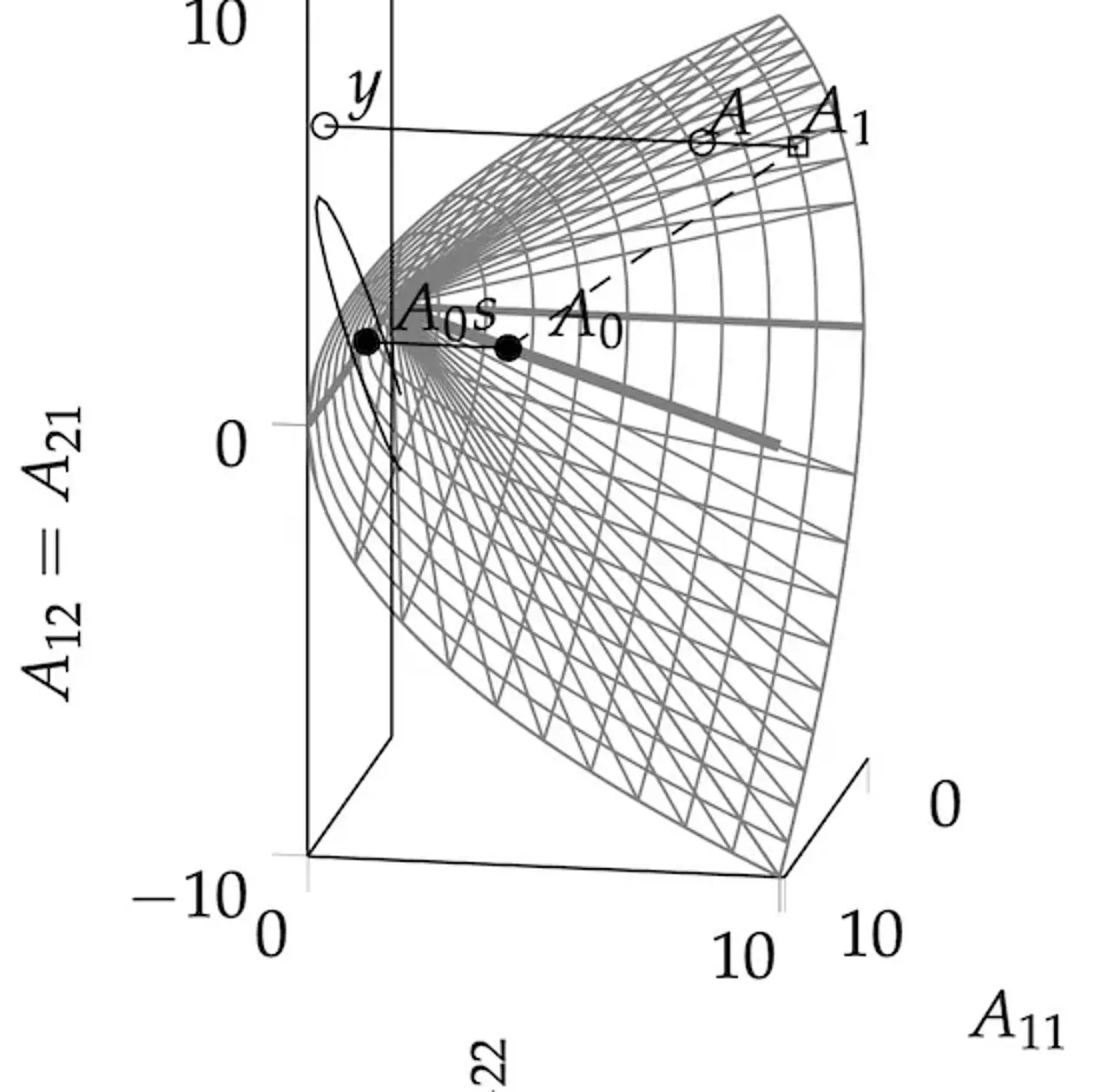
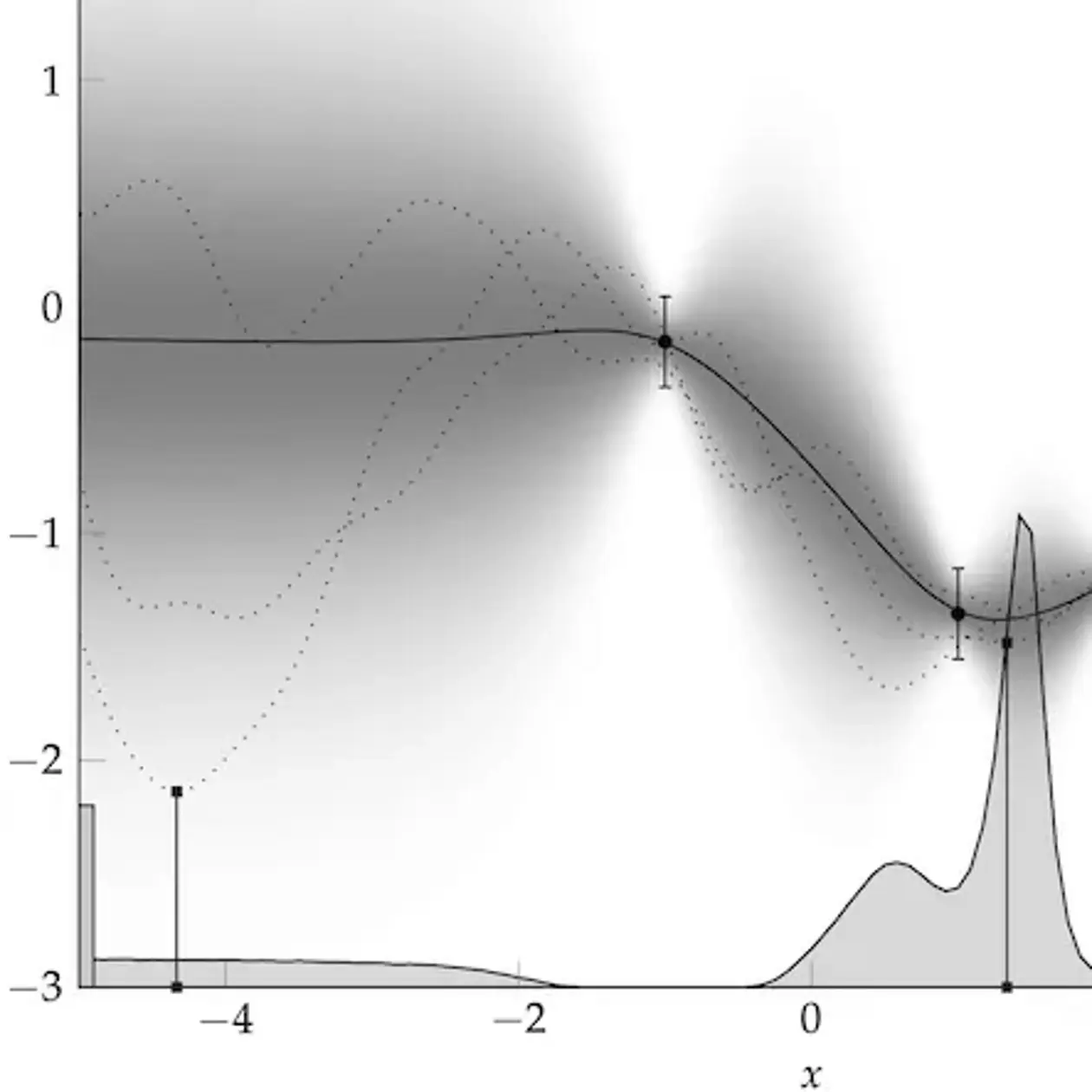
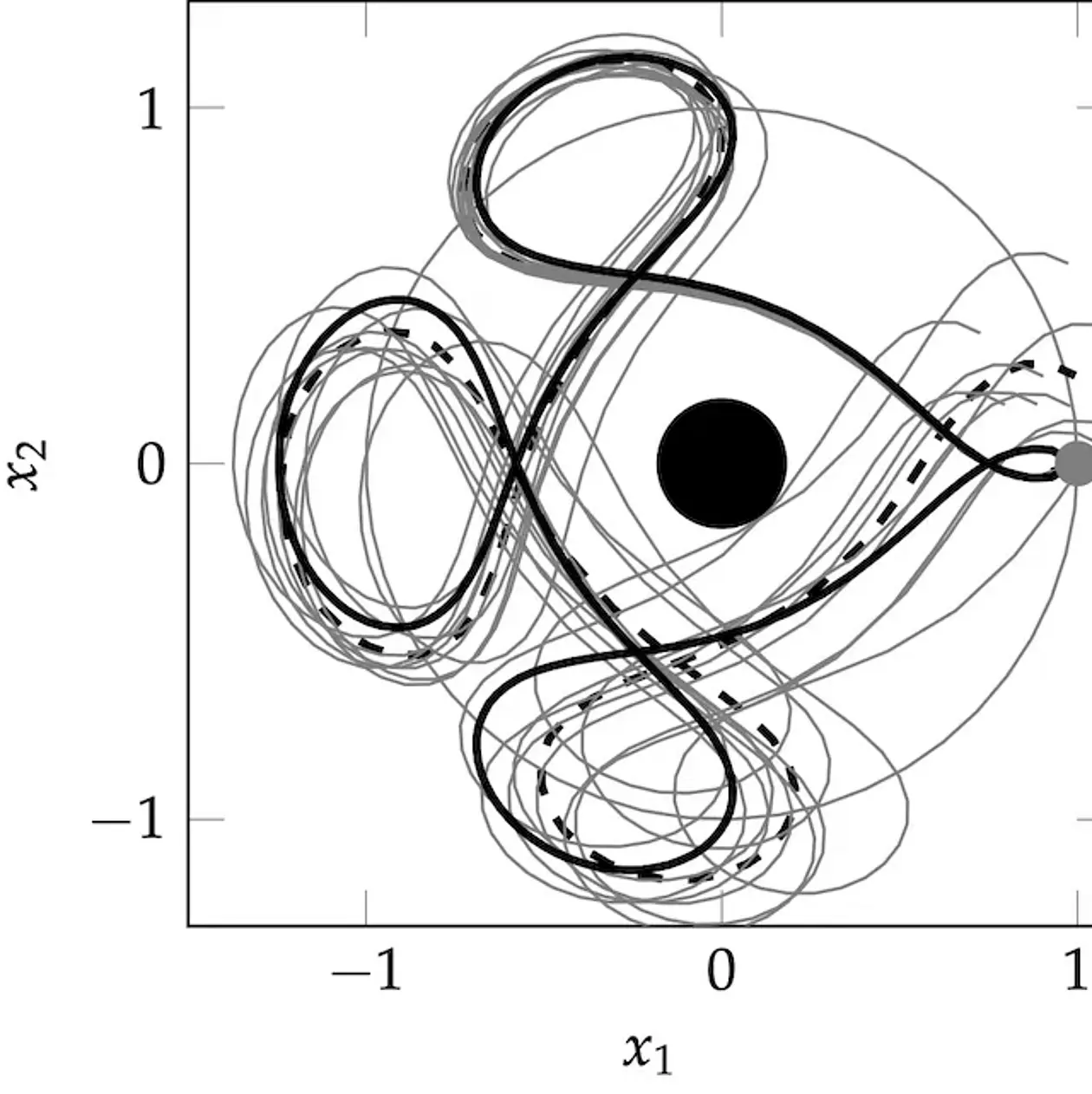
Machine learning, in contrast to classic, rule-based AI, describes learning as a statistical inference problem. Solving this problem in a concrete machine requires the solution of numerical problems: Optimization (finding the best explanation for data), Integration (to measure evidence) and Simulation (to predict the future). Applied mathematics has invented great algorithmic tools for this purpose. The core tenet of our group's work is the insight that these numerical methods are themselves elementary learning machines. To compute a non-analytic numerical result means using the result of tractable (observable) computations — data — to infer the unknown number. Since numerical methods also actively decide which computations to perform to efficiently solve their task, they really are autonomous agents. So it must also be possible to describe their behavior in the mathematical terms of learning machines. When this is done in the probabilistic framework, we call the resulting algorithms probabilistic numerical methods. They are algorithms that take as their input a generative model describing a numerical task, use computing resources to collect data, perform Bayesian inference to refine the generative model and return a posterior distribution over the target quantity. This distribution can then be studied, analogous to how point estimates are studied in classic numerical analysis: The posterior should concentrate around the correct value (e.g. its mean should be close to the true value, and the standard deviation should relate to the distance between truth and mean), and the concentration should be "fast" in some sense. The theoretical work in the group focusses on developing such methods and using them to provide novel, much-needed functionality for contemporary machine learning and beyond.