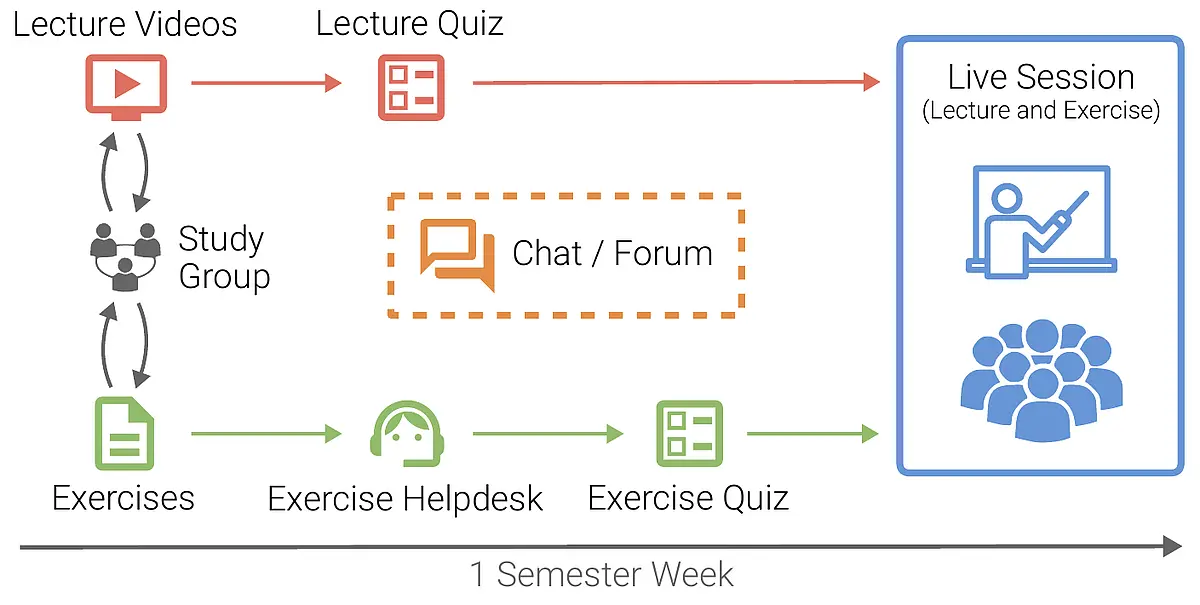
Date | Lecture Slides and Videos | Live Sessions | TA Support |
| | Recap: Math for Deep Learning | | |
16.04. | L01 - Introduction | Slides 1.1 Organization | Video 1.2 Introduction | Video 1.3 History of Computer Vision | Video | L01 - Lecture Organization
E01 - Exercise Introduction | Problems | Gege Gao |
23.04. | L02 - Image Formation | Slides
2.1 Primitives and Transformations | Video 2.2 Geometric Image Formation | Video
2.3 Photometric Image Formation | Video
2.4 Image Sensing Pipeline | Video | L02 - Lecture Q&A
E01 - Exercise Q&A | Gege Gao |
30.04. | L03 - Structure-from-Motion | Slides 3.1 - Preliminaries| Video 3.2 - Two-frame Structure-from-Motion| Video 3.3 - Factorization | Video 3.4 - Bundle Adjustment | Video | L03 - Lecture Q&A E01 - Exercise Q&A E02 - Exercise Introduction | Problems | Gege Gao
Patricia Gschoßmann |
07.05. | L04 - Stereo Reconstruction | Slides 4.1 - Preliminaries | Video 4.2 - Block Matching | Video 4.3 - Siamese Networks | Video 4.4 - Spatial Regularization | Video 4.5 - End-to-End Learning | Video | L04 - Lecture Q&A E02 - Exercise Q&A | Patricia Gschoßmann |
14.05. | L05 - Probabilistic Graphical Models | Slides 5.1 - Structured Prediction | Video 5.2 - Markov Random Fields | Video 5.3 - Factor Graphs | Video 5.4 - Belief Propagation | Video 5.5 - Examples | Video | L05 - Lecture Q&A E02 - Exercise Q&A
E03 - Exercise Introduction | Problems | Patricia Gschoßmann |
21.05. | L06 - Applications of Graphical Models | Slides 6.1 - Stereo Reconstruction | Video 6.2 - Multi-View Reconstruction | Video 6.3 - Optical Flow | Video | L06 - Lecture Q&A E03 - Exercise Q&A | Patricia Gschoßmann |
28.05. | L07 - Learning in Graphical Models | Slides 7.1 - Conditional Random Fields | Video 7.2 - Parameter Estimation | Video 7.3 - Deep Structured Models | Video | L07 - Lecture Q&A E03 - Exercise Q&A
E04 - Exercise Introduction | Problems | Patricia Gschoßmann Christina Tze |
04.06. | L08 - Shape-from-X | Slides 8.1 - Shape-from-Shading | Video 8.2 - Photometric Stereo | Video 8.3 - Shape-from-X | Video 8.4 - Volumetric Fusion | Video | L08 - Lecture Q&A E04 - Exercise Q&A | Christina Tze |
| | Break | Break | |
18.06. | L09 - Coordinate-based Networks | Slides 9.1 - Implicit Neural Representations | Video 9.2 - Differentiable Volumetric Rendering | Video 9.3 - Neural Radiance Fields | Video 9.4 - Generative Radiance Fields | Video | L09 - Lecture Q&A E04 - Exercise Q&A
E05 - Exercise Introduction | Problems | Christina Tze |
25.06. | L10 - Recognition | Slides 10.1 - Image Classification | Video 10.2 - Semantic Segmentation | Video 10.3 - Object Detection and Segmentation | Video | L10 - Lecture Q&A E05 - Exercise Q&A | Christina Tze |
| | Break | Break | |
09.07. | L11 - Self-Supervised Learning | Slides 11.1 - Preliminaries | Video 11.2 - Task-specific Models | Video 11.3 - Pretext Tasks | Video 11.4 - Contrastive Learning | Video | L11 - Lecture Q&A E05 - Exercise Q&A
E06 - Exercise Introduction | Problems | Gege Gao Christina Tze |
16.07. | L12 - Diverse Topics in Computer Vision | Slides 12.1 - Input Optimization | Video 12.2 - Compositional Models | Video 12.3 - Human Body Models | Video 12.4 - Deepfakes | Video | L12 - Lecture Q&A E06 - Exercise Q&A | Gege Gao |