Our research is focused on 3D scene understanding, reconstruction, motion estimation, generative modeling and sensori-motor control in the context of autonomous systems. Our goal is to make artificial intelligent systems such as self-driving cars or household robots more autonomous, efficient, robust and safe. By making progress towards these goals, we also strive for uncovering the fundamental concepts underlying visual perception and autonomous navigation. Moreover, we work on integrating language with vision and robotics, and we do research on scientific document process to help researchers become more efficient. Our research is guided by the following principles.
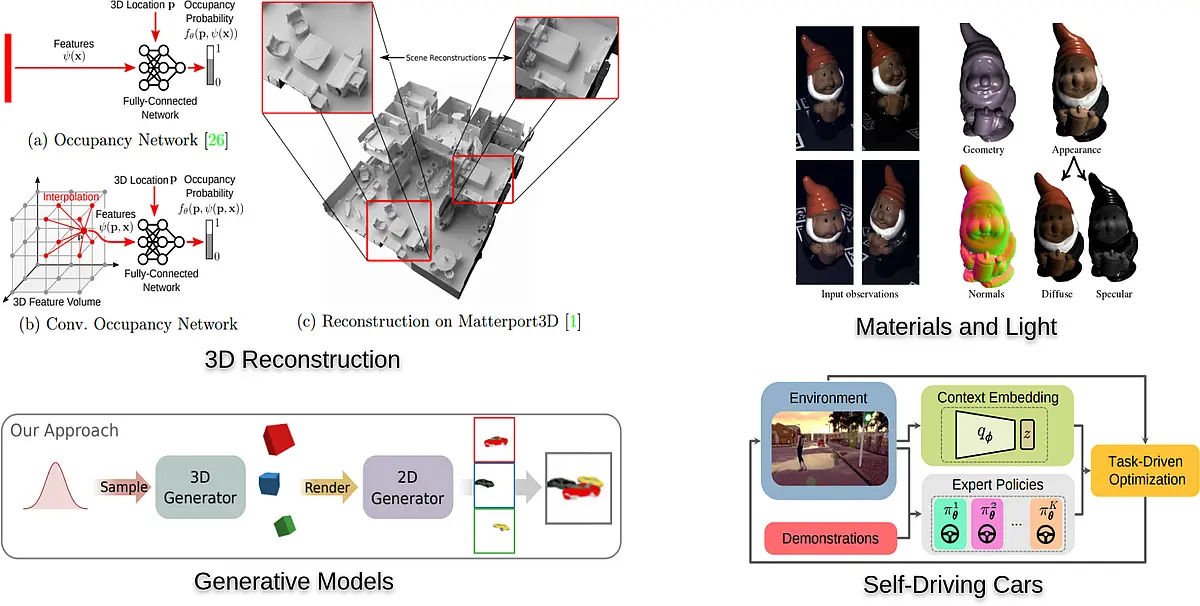
- Representations: Our world is inherently three-dimensional as all physical processes (including image formation) occur in 3D and not in the 2D image plane. Thus, we strive for inferring compact 3D representations of our world from 2D or 3D measurements. To this end, we develop novel scalable spatio-temporal representations, learning frameworks, reconstruction as well as motion estimation algorithms.
- Prior Knowledge: Visual perception is a highly ill-posed task with many explanations for a single observation. We therefore investigate how prior knowledge (e.g., about the shape of objects, image formation or driving laws) can be incorporated into visual perception and autonomous navigation to make both tasks more robust. We also develop probabilistic representations which capture uncertainty in the output.
- Learning from Little Data: High-capacity models such as deep neural networks require large amounts of annotated training data which limits scalability. To address this problem, we develop novel techniques for learning from little annotated data, including self-supervised models for geometry and motion estimation, methods for transferring labels across domains, techniques which incorporate a-priori knowledge into the structure of neural networks and approaches that explicitly model invariances in the data.
- Generative Models and Simulation: Generative models are at the core of understanding the fundamental processes underlying vision, building robust models and generating large amounts of training data for discriminative models. We investigate generative models (such as GANs and VAEs) from a theoretical perspective and apply them to tasks in the context of data generation for autonomous driving and beyond. See the LEGO-3D project page for more information about our ERC Starting Grant project.
- Empirical Risk Minimization: Many state-of-the-art computer vision models (e.g., 3D reconstruction) or sensori-motor control systems (e.g., self-driving cars) are trained using auxiliary loss functions instead of the actual task loss due to difficulties in representation or computational limitations. We work on end-to-end trainable models for these tasks which exploit task information in a data-efficient manner.
- Datasets and Evaluation: We strongly believe that research is a collective effort that is only possible by sharing research results, code and data. We are therefore committed to publishing our results and code. Moreover, we construct novel datasets like KITTI, KITTI-360 or ETH3D to foster progress in the field and across research areas
- Scientific Discovery: We are conducting natural language processing and computer vision research on scientific discovery. Our goal is to build and deploy tools such as Scholar Inbox to facilitate and accelerate the research cycle itself.
For more information, visit our publications page. You can also follow us on our Blog, on GoogleScholar and on YouTube.