Network Projects
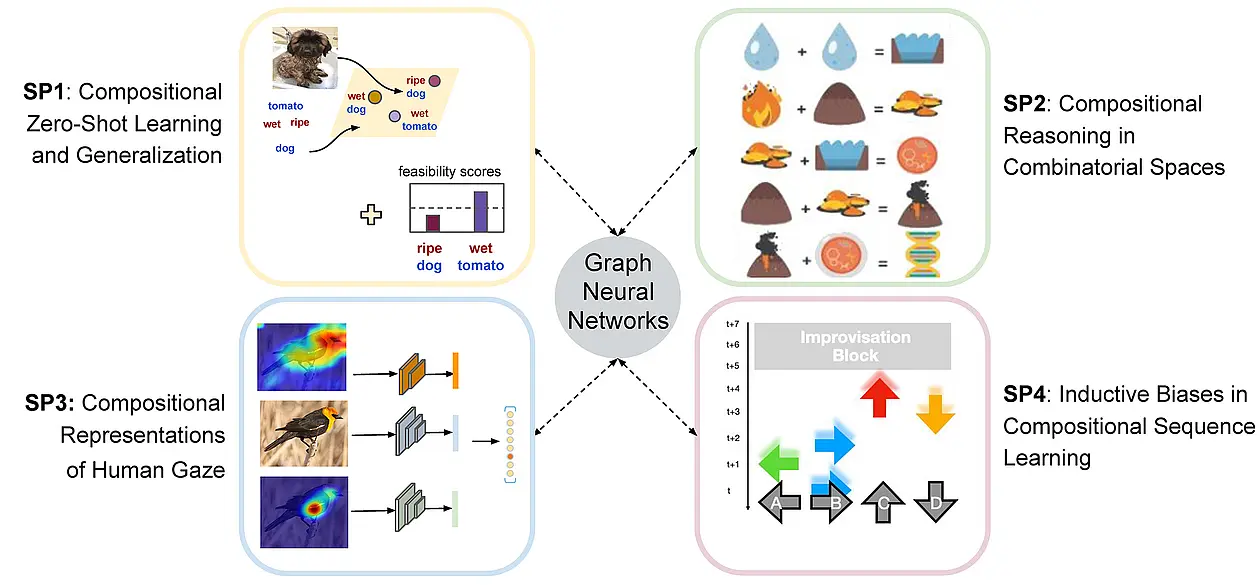
SP 3
Compositional Representations of Human Gaze

SP 3
Adaptivity and personalized learning in the flow
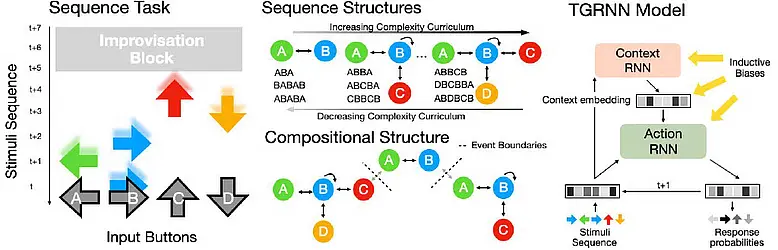
SP 4
Ethics, Privacy, and Fairness in digital education environments
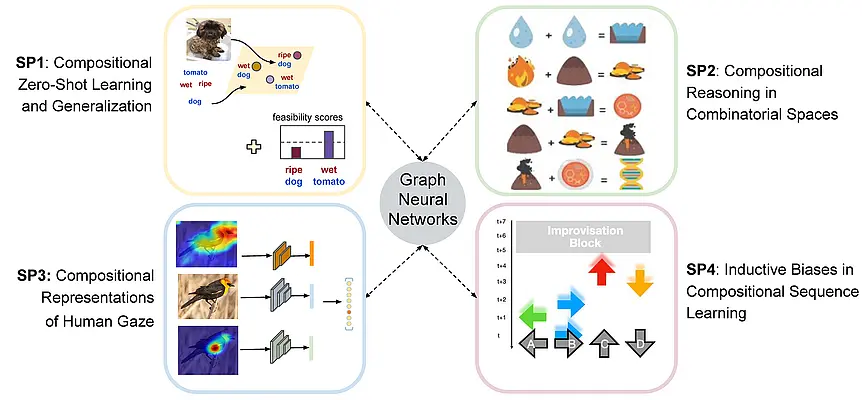
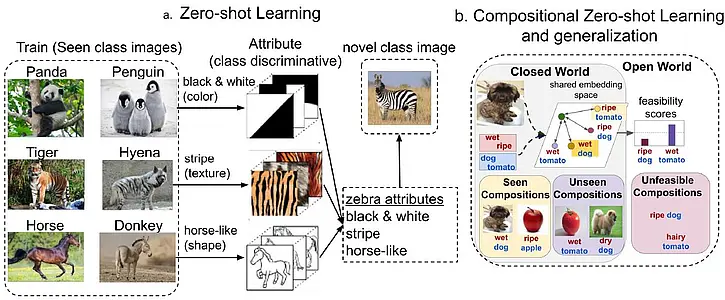
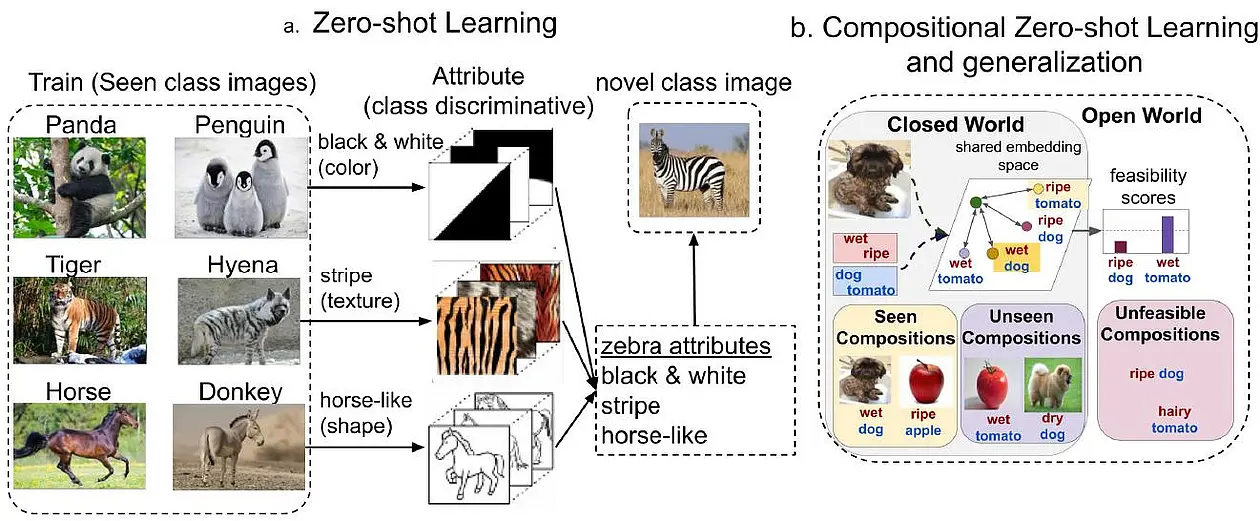
SP 1
Seasonal weather forecast
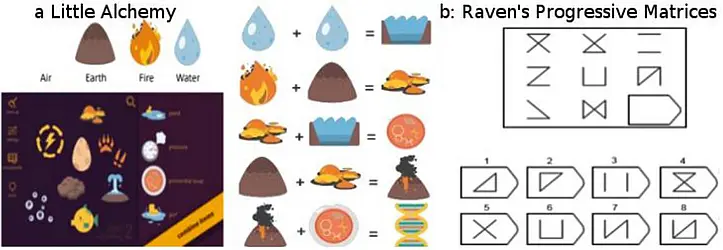
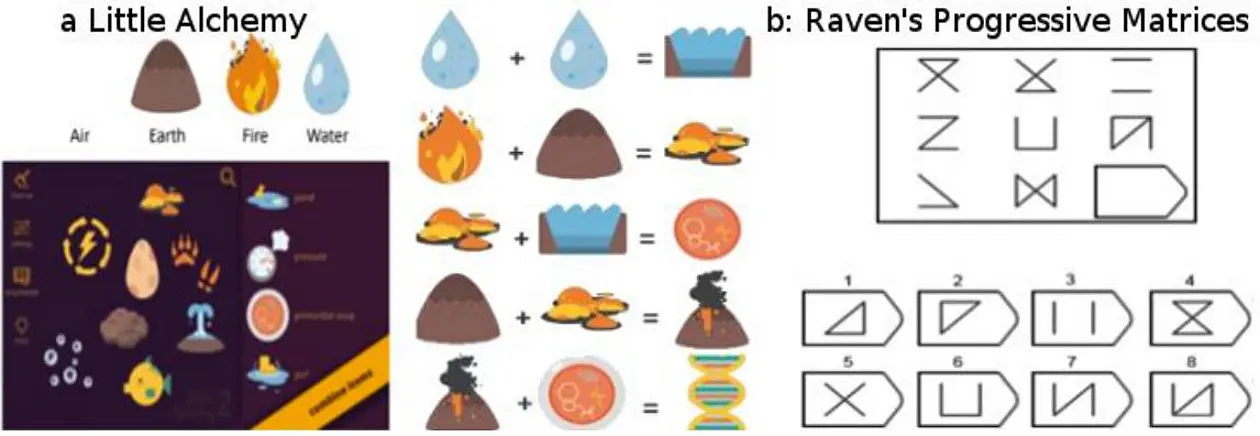
SP 2
Water discharge prediction
SP 3
Modeling soil erosion
SP 4
Solar thermal systems
SP 1
Inferring landscape development processes
SP 2
Unravelling the ice dynamic, atmospheric and oceanographic history of ice-sheets with Bayesian inference
SP 3
Efficient inference and simulation for mechanistic models in neuroscience
SP 4
Inference of predictive genome wide mechanistic models of cellular differentiation from single-cell transcriptomics with gradient information
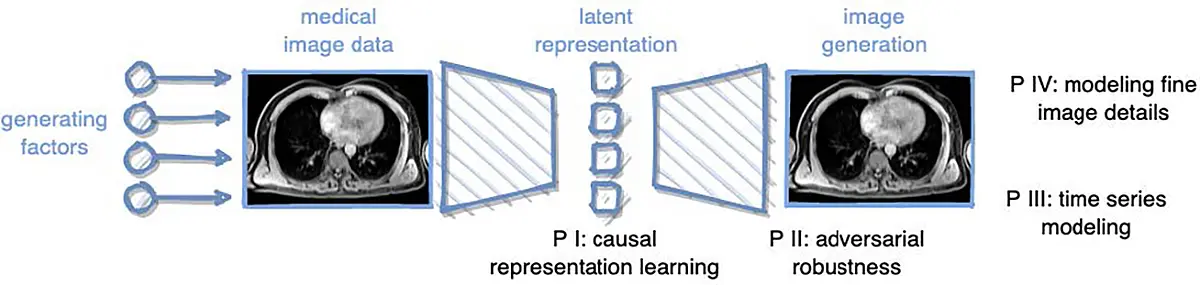
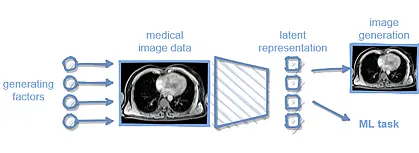

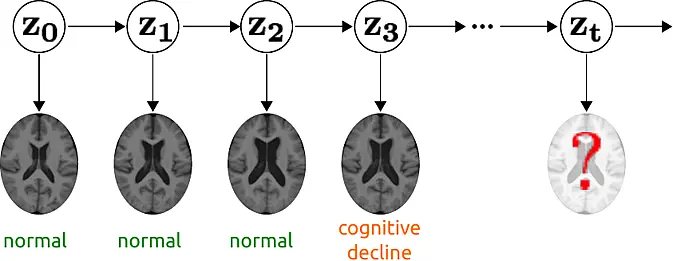
SP 4
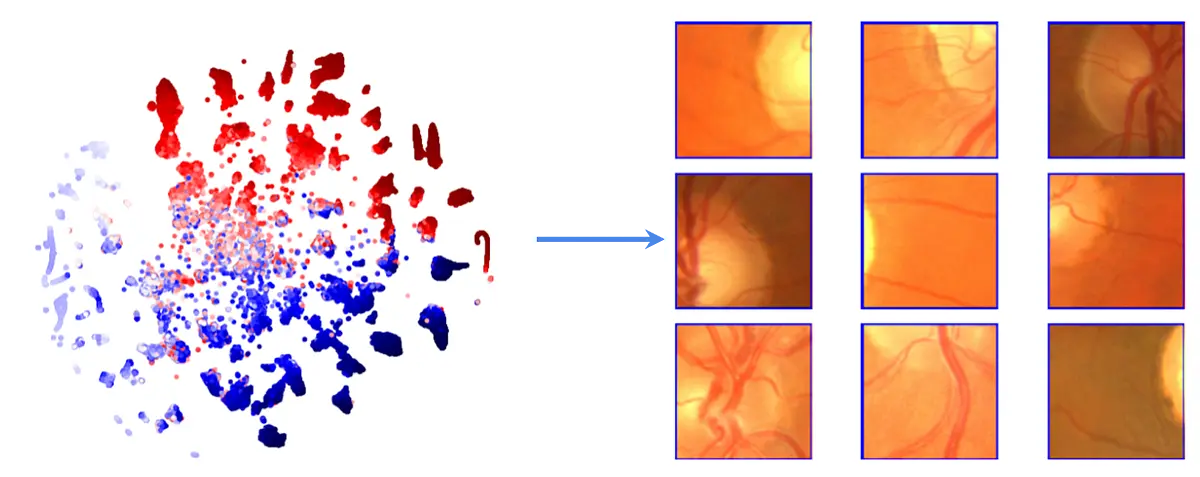
Understanding the structure of fundus images in ophthalmologyusing hybrid generative models including the physical imaging process
- Principal investigators: Philipp Berens1· philipp.berens@uni-tuebingen.de · berenslab.org
Hendrik Lensch2· hendrik.lensch uni-tuebingen.de · Website
uni-tuebingen.de · Website
- Team member: Sarah Müller1 (PhD student)
1University Hospital Tübingen, Institute for Ophthalmic Research, 2University of Tübingen, Department of Computer Science
Project duration: April 2021 - March 2025
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}