Network Projects
With the format of network projects, we want to specifically target research priorities in which the development and application of machine learning methods to specific problems from different scientific disciplines is advanced. The goal of this format is to deepen the dialog between the different scientific disciplines, that join together in a kind of Mini Graduate School. Our currently 5 funded network projects consist of 4 subprojects (SP) each, in which different research groups work together on the following, overarching topics.
Compositionality in Minds and Machines
Machine Learning in Education
Modeling and Understanding Spatiotemporal Environmental Interactions (MUSTEIN)
Probabilistic Inference in Mechanistic Models (PIMMS)
Uncovering the inner structure of medical images through generative modeling
► Compositionality in Minds and Machines
Compositionality makes all interesting computation possible. By combining and recombining smaller parts into a meaningful whole, compositionality boosts generalization, reduces sample complexity, and improves interpretability. From convolutional networks to structured probabilistic inference, many frameworks can be modelled as compositional functions for pattern recognition, reasoning, and planning. Indeed, inferring good models from limited training sets — and all training sets are limited — fundamentally requires compositionality.
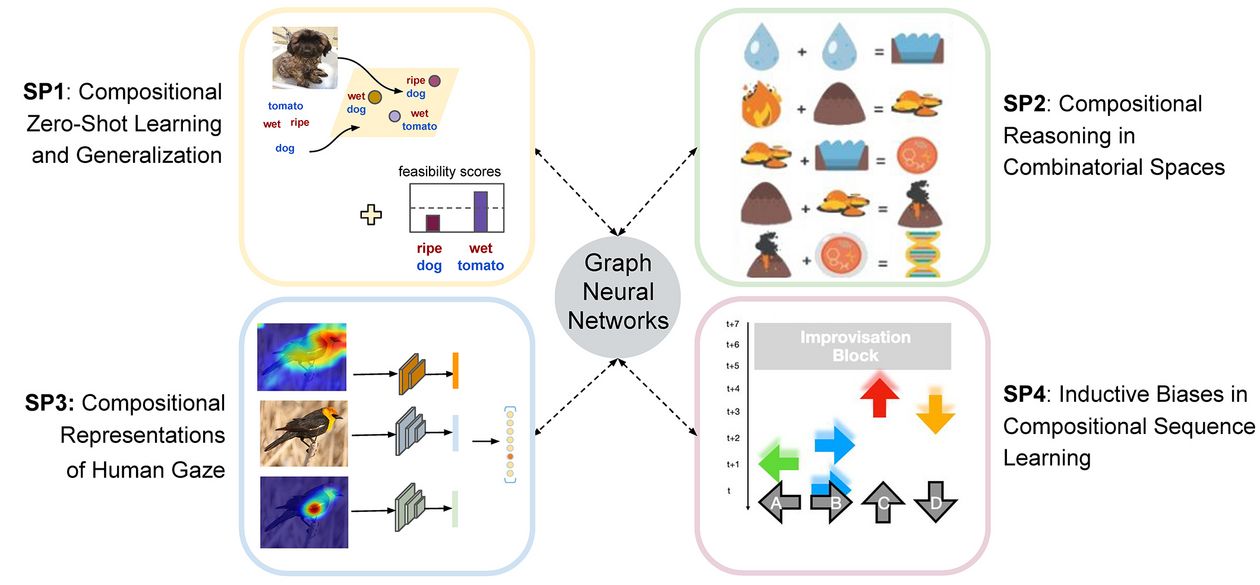
In this Network Project, across 4 Subprojects (SP) we bridge different disciplines to create models of compositional reasoning in minds and machines: In SP 1, we work towards a model that can perform common-sense compositional zero-shot generalization in open world scenarios. In SP 2, we build models that can reason compositionally to explore their environment and solve abstract intelligence tasks in a human-like fashion. In SP 3, we use the compositional nature of human gaze to improve fine-grained classification. In SP 4, we study which inductive biases allow humans to learn and compositionally reuse latent structures.
{kind=link}
SP 1
Compositional Zero-Shot Learning, Disentangling Representations and Generalization
- Principal Investigators: Zeynep Akata1 · zeynep.akata@uni-tuebingen.de · eml-unitue.de
Eric Schulz2 · eric.schulz@tuebingen.mpg.de · cpilab.org
Matthias Bethge3,4 · matthias@bethgelab.org, bethgelab.org
- Team member: Shyamgopal Karthik1 (PhD student)
University of Tübingen, 1Cluster of Excellence Machine Learning, 3Department of Physics, 4Tübingen AI Center
2Max Planck Institute for Biological Cybernetics, Tübingen
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Deep neural networks (DNN) struggle with compositional generalization because they often build on attributes that are correlated with each other even if they are not ”essential'' for the class. This leads to consistent misclassification of samples from a new distribution. Indeed, different objects in the same state appear differently, e.g., the state “wet'' changes the objects “car'' and “cat'' differently. Building models that reason like humans for unseen compositions is therefore challenging.
In this Subproject, we want to break down the task of compositionality to learning latent representations of objects and states and then the joint distribution of their compositions through a graph neural network allowing robust generalisation to both seen and novel compositions.
{kind=link}
SP 2
Compositional reasoning in combinatorial spaces
- Principal Investigators: Eric Schulz1 · eric.schulz@tuebingen.mpg.de · cpilab.org
Zeynep Akata2 · zeynep.akata@uni-tuebingen.de · eml-unitue.de
Peter Dayan1 · dayan@tue.mpg.de · webpage
- Team member: Tankred Saanum1 (PhD student)
1Max Planck Institut for Biological Cybernetics, Tübingen, 2University of Tübingen, Cluster of Excellence Machine Learning
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
The goal of this Subproject is to develop a model, combining combining cognitive science and machine learning, that can perform higher-level cognitive tasks that involve basic reasoning of semantic and rule-like compositions. One testbed for this endeavor will be the popular game “Little Alchemy”. In this game, players start out with four basic elements: Water, fire, earth, and air. Players can select pairs of elements to combine, e.g. fire and water, which sometimes lead to new elements, e.g. steam, and can produce increasingly complex elements. On our large data set from 30.415 players, we will use graph neural networks which directly operate on a learned graphical representation of the game tree to classify nodes as possible offsprings of two elements. Paired with a semantic space of word embeddings, this model will learn to compose elements to create new elements, and thereby play the game from scratch.
{kind=link}
SP 3
Compositional Representations of Human Gaze
- Principal Investigators: Enkelejda Kasneci1 · enkelejda.kasneci@uni-tuebingen.de · www.hci.uni-tuebingen.de
Zeynep Akata2 · zeynep.akata@uni-tuebingen.de · eml-unitue.de
Felix Wichmann1 · felix.wichmann@uni-tuebingen.de · wichmannlab.org
- Team members: Michael Kirchhoff1 (PhD student)
University of Tübingen, 1Department of Computer Science, 2Cluster of Excellence Machine Learning
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Our aim for this subproject is three fold. First we propose a reveal test to evaluate if the gradient-based attention models are faithful to the decision and the automatically extracted machine attention aligns with the human attention. Second, we will investigate if human attention can be efficiently combined with machine attention to boost the accuracy of decision makers while being faithful to the real underlying reasons for the decision. Third, we will investigate bottom-up and top-down as well as low-level and high-level factors that influence where humans fixate when viewing natural scenes.
SP 4
Inductive Biases in Compositional Sequence Learning
- Principal Investigators: Charley Wu1 · charley.wu@uni-tuebingen.de · hmc-lab.com
Martin Butz2 · martin.butz@uni-tuebingen.de · cm.inf.uni-tuebingen.de
Eric Schulz3 · eric.schulz@tuebingen.mpg.de · cpilab.org
- Team Member: Lee Sharkey1 (PhD student)
University of Tübingen, 1Cluster of Excellence Machine Learning, 2Department of Computer Science
3Max Planck Institut for Biological Cybernetics, Tübingen
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
We propose a sequence generation task, where human participants are shown visual cues, corresponding to button presses that must be made in rapid succession. Stimuli only appear briefly, such that performance depends on learning the structural regularities of sequences. Sequences are generated based on hidden graph structures, where higher-order graphs are composed of simpler subgraphs, and participants will be shown curricula of either increasing or decreasing complexity. In addition to cued sequence learning, participants will also be asked to “improvise” pattern completions in the absence of stimuli, which will provide valuable insight into the development of prior expectations about structured sequences.
{kind=link}
► Machine Learning in Education
Education is designed to foster learning in complex, real-life environments. Learners, however, differ substantially in many respects, including social, cognitive, and motivational factors, and their prior knowledge in the target domain.
Education needs to take this substantial heterogeneity into account. With the increasing use of Intelligent Tutoring Systems (ITS) in real-life education, using machine learning to optimally support individual learning is becoming feasible. Yet, we still lack the ability to
(1) interpret rich learning process data digitally collected in real-life education contexts in a way that supports an understanding of learning outcomes based on the characteristics of individual learners and learning activities. On this basis, optimally supporting individual learners then requires,
(2) taking the structure of the knowledge domain into account, and
(3) adaptively sequencing activities to best match individual skills and challenges. While ML methods are promising for addressing these gaps, we need to consider
(4) how determining learning opportunities based on ML models can be designed to be fair, and how to handle rich learner and learning-process data in a privacy-respecting way.
In this Network Project, we address these four intertwined research gaps, where interdisciplinary collaboration and the advancement of machine learning methods is crucial, within 4 Subprojects (SP1-SP4 below).
SP 1
Advancing Learning Analytics: Understanding learning outcomes
- Principal Investigators: Detmar Meurers1 · dm@sfs.uni-tuebingen.de · website
Bob Williamson2 · bob.williamson@uni-tuebingen.de · website
Kou Murayama3 · k.murayama@uni-tuebingen.de · website
- Team member: NN1 (PhD student)
University of Tübingen, 1Seminar for Linguistic Sciences, 2Department of Computer Science
3Hector Research Institute of Education Sciences and Psychology
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
While fine-grained and rich learning process data can be collected in Intelligent Tutoring Systems (ITS), learning analytics has mostly focused on general outcome variables, such as who is likely to fail a class, not on the learning process and understanding the variables shaping it. At the same time, education research has struggled to take advantage of ITS data because common statistical tools used there are mostly designed to deal with linear relationships between a limited number of variables, and they struggle to account for the substantial noise common in ecologically-valid data.
This Subproject is designed to overcome this deadlock by (1) bringing together interdisciplinary insights about learner and learning variables during real-life learning and leveraging machine learning advances to (2) improve correlational models and (3) seek opportunities for a quantitative evaluation of interventions via causal modeling.
SP 2
Modeling learning in structured domains
- Principal Investigators: Álvaro Tejero-Cantero1 · alvaro.tejero@uni-tuebingen.de · mlcolab.org
Charley Wu1 · charley.wu@uni-tuebingen.de · hmc-lab.com
- Co-Advisors: Detmar Meurers, Kou Murayama, and Ulf Brefeld
- Team member: Hanqi Zhou1 (PhD student)
1University of Tübingen, Cluster of Excellence Machine Learning, 2Department of Computer Linguistics,
3Hector Research Institute of Education Sciences and Psychology, 4Leuphana University,
Institute for Information Systems
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Our approach in this project can be conceptualized as a Bayesian active learning scheme for human learners that leverages structural knowledge while accounting for the dynamics of human memory.
We aim to (1) develop scalable methods for inferring knowledge structures from text, and (2) build a Structured Spaced Repetition (SSR) system that adaptively schedules self-testing based on both prior interactions and the domain knowledge graph. We will use experimental methods to (3) empirically validate the SSR against alternative learning methods, where in cooperation with SP1, the interaction data will also be used to better understand the mechanisms underlying compositional learning in humans. Lastly, (4) we will release an open-source scheduling API and enable long-term research on structured adaptive learning by providing observational data and algorithmic validation with real learners.
SP 3
Adaptivity and personalized learning in the flow
- Principal Investigators: Enkelejda Kasneci1 · enkelejda.kasneci@uni-tuebingen.de · www.hci.uni-tuebingen.de
Detmar Meurers2 · dm@sfs.uni-tuebingen.de · https://uni-tuebingen.de/en/134140
- Team member: Efe Bozkir1 (PhD student)
University of Tübingen, 1Department for Computer Science, 2Seminar for Linguistic Sciences
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
To adaptively support individual learners, we must be able to (1) select the activities that best foster learning for the individual, (2) support (“scaffold”) them in tackling the activity, and (3) keep them engaged in this activity and on the overall learning path.
In this Subproject we develop machine learning methods that support dynamic sequencing of learning activities in Intelligent Tutoring Systems (ITS) by linking rich learner models with high-dimensional models of activity complexity. Our focus is on the dynamic match between the learner variables (traits and current cognitive and motivational state) and learning activity complexity. While some relevant variables can be explicitly measured with short game-like tests (e.g., working memory capacity), others must be inferred as latent variables: affective states (e.g., attention; engagement and emotions derived from visually observable features, keyboard and mouse interaction), physiological data, and cognitive load.
SP 4
Ethics, Privacy, and Fairness in digital education environments
- Principal Investigators: Konstantin Genin1 · konstantin.genin@uni-tuebingen.de · kgenin.github.io
Thomas Grote1 · thomas.grote@uni-tuebingen.de · website
Benjamin Nagengast2 · benjamin.nagengast@uni-tuebingen.de · website
Bob Williamson3 · bob.williamson@uni-tuebingen.de · website - Team member: Vlasta Sikimic1 (PhD student)
University of Tübingen, 1Cluster of Excellence Machine Learning, 2Hector Research Institute of Education
Sciences and Psychology, 3Department of Computer Science
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
The application of machine learning methods in digital education raises significant ethical issues. Adaptive learning systems promise to be particularly useful for disadvantaged students without adequate family support and could thus contribute to the reduction of educational inequalities. However, students who stand to benefit the most are also the least able to advocate for themselves. Accordingly, special care must be taken to treat students fairly and protect their privacy.
Inevitably, trade-offs will emerge between privacy and the effective development and testing of algorithmic interventions. Moreover, trade-offs will emerge between population-level effectiveness of algorithmic interventions and their effectiveness in sub-populations. A fine-grained understanding of such trade-offs is required to manage them with the necessary sensitivity in modeling.
In this respect, Subproject 4 addresses four areas of particular importance Privacy, Beneficence, Equipoise, Fairness, combining ethical and methodological work in close connection with the other subprojects.
► Modeling and Understanding Spatiotemporal Environmental Interactions (MUSTEIN)
Our world changes rapidly due to mankind creating the “Anthropocene”. Increasing greenhouse gas concentrations (including CO2 and methane) in the atmosphere lead to climate change. Intensive irrigation, agriculture generally, grubbing, dam building, and impervious surfaces, severely affect our hydrosphere – including our freshwater resources – as well as our biogeosphere – including unprecedented rates of soil erosion. Meanwhile, humans demand more energy in their anthroposphere, while relying on safe and rewarding habitats as well as on sufficient food and water resources.
The Network Project MUSTEIN aims at developing machine learning techniques that reliably learn explainable models of critical aspects of these four highly interacting spheres, focusing in 4 Subprojects (SP) on seasonal weather dynamics (SP1), river water discharge (SP2), soil erosion (SP3), and solar thermal systems (SP4).
SP 1
Seasonal weather forecast
- Principal Investigators: Bedartha Goswami1 · bedartha.goswami@uni-tuebingen.de · website
Martin Butz2 · martin.butz@uni-tuebingen.de · https://cm.inf.uni-tuebingen.de/
Hendrik Lensch2 · hendrik.lensch@uni-tuebingen.de · website
Nicole Ludwig3 · nicole.ludwig@uni-tuebingen.de · https://nicoleludwig.github.io/
- Team members: Jannik Thuemmel1(PhD student)
University of Tübingen, 1Cluster of Excellence Machine Learning, 2Department of Computer Science, 3ML in Sustainable
Energy Systems
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
While reliable seasonal forecasts would be immensely helpful (e.g. for planting decisions in agriculture), even state-of-the-art long range forecast systems such as SEAS5 have limited success in case of rainfall. Particularly, predictions of extreme precipitation seem out of reach. Indeed, seasonal predictions of precipitation suffer from a low signal-to-noise ratio in current climate models. In addition, current climate models underestimate the predictability of large-scale oscillations, such as the North Atlantic Oscillation (NAO), which strongly influence the climate of western Europe, and which in turn are critically affected by heavy tropical rainfall events that occurred several months earlier.
This project aims to develop seasonal forecast models via machine learning, with a focus on extreme rainfall events in Germany. In particular, we will develop spatiotemporally-predictive, generative graph artificial neural networks (STANNs) that will take multiple data sources into account and that will process both short- and long-range influences in space and time in a modularized manner.
SP 2
Water discharge prediction
- Principal Investigators: Martin Butz1 · martin.butz@uni-tuebingen.de · website
Christiane Zarfl2 · christiane@zarfl@uni-tuebingen.de · website
- Team members: Fedor Scholz1(PhD student)
University of Tübingen, 1Department of Computer Science, 2Department of Geosciences
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Rivers are dynamic and highly connected systems that react to weather events in dependence of their surrounding geology and vegetation, climate zone, and human imprinting (river regulation, fragmentation, channelization etc.). River water discharge and current water level, which are measured at gauging stations, enable inferences about water quality, ecosystem status, and even suitability as a freshwater habitat.
In this project, we aim at developing a machine learning approach in combination with available process model knowledge that improves discharge predictions and thus our ability to anticipate, and thus prepare for critical discharge events. The model will also be applied to infer particular factors and factor combinations that best explain the reasons behind particular discharge behavior, thus enabling us to control dangerous hydrological dynamics in a model-predictive manner.
SP 3
Modeling soil erosion
- Principal Investigators: Thomas Scholten1 · thomas.scholten@uni-tuebingen.de · website
Martin Butz2 · martin.butz@uni-tuebingen.de · https://uni-tuebingen.de/de/25369
Georg Martius3 · georg.martius@tuebingen.mpg.de · http://al.is.mpg.de
- Team members: Manuel Traub1 (PhD student)
University of Tübingen, 1Department of Geosciences, 2Department of Computer Science
3Max Planck Institute for Intelligent Systems, Tübingen
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Soil erosion is a process system of human-environment interaction and as such a typical ecosystem response to human activities. About two thirds of the arable land is affected. Particularly, also climate change with its predicted increase of extreme weather events (e.g. droughts and precipitation intensity) will strongly influence future soil erosion rates. Current prediction models are limited to small areas or in temporal resolution
In this Subproject, we aim at improving currently available process models to (i) generate more accurate predictions of soil erosion dynamics in the light of precipitation and (ii) infer and interpret erosion-determining factors by analyzing landscape structure and the influence of human activity in unprecedented manners. We will do so by developing a STANN-based forecast model to predict soil erosion dynamics. The model will integrate available data on elevation, landscape structure, and land usage, as well as high-resolution (5 min) rainfall intensity data. Additionally, soil erosion features will be considered.
SP 4
Solar thermal systems
- Principal investigators: Volker Franz1 · volker.franz@uni-tuebingen.de · website
Carl-Johann Simon-Gabriel2 · cjsg@ethz.ch · website
Georg Martius3 · georg.martius@tuebingen.mpg.de · http://al.is.mpg.de/
Nicole Ludwig4 · nicole.ludwig@uni-tuebingen.de · https://nicoleludwig.github.io
- Team members: Florian Ebmeier1 (PhD student)
University of Tübingen, 1Department of Computer Science, 4Cluster of Excellence Machine Learning
2Learning & Adaptive Systems, ETH Zürich, 3Max Planck Institute for Intelligent Systems, Tübingen
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Providing heating and hot water for buildings contributes considerably to the carbon dioxide emissions in Germany. Solar thermal systems could substantially reduce these emissions. However, the use of such systems is wanting and has even been in decline, which seems partially due to problems in quality control and efficiency. We aim to improve solar thermal systems using machine learning techniques that employ spatiotemporal sensor data as well as meteorological data.
► Probabilistic Inference in Mechanistic Models (PIMMS)
Numerical models are at the heart of scientific understanding in many disciplines. In geoscience, numerical models are used to describe geophysical processes; in neuroscience, they provide a testbed of our mechanistic understanding of physiological processes; and in systems cell biology they are used to describe regulatory networks of genes or proteins. Typically such mechanistic models come as systems of differential equations, be it ordinary differential equations (ODEs), simulating a spatial process through time, or partial differential equations (PDEs), simulating a process through both time and space.
In 4 Subprojects (SPs, see below), we want to apply currently available probabilistic numerical tools to difficult problems in these three scientific disciplines where ODE/PDE models are paramount. Through these diverse scientific application fields, our primary objective is the development of a general toolbox for probabilistic inference techniques for mechanistic models that will be applicable across disciplines for decades to come.
SP 1
Inferring landscape development processes
- Principal Investigators: Todd Ehlers1 · todd.ehlers@uni-tuebingen.de · esdynamics.net
Philipp Hennig2 · philipp.henig@uni-tuebingen.de · mml.inf.uni-tuebingen.de
- Team members: Schmidt Jonathan2 (PhD student)
University of Tübingen, 1Department of Geosciences, 2Department of Computer Science
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
In geoscience, fascinating advances have been made in the development of landscape evolution models in the past decade. These physics (PDE) based models predict the transient evolution of topography as a function of plate tectonic, climate change, and vegetation change impacts on erosion and sedimentation. This is done using a modified form of the transient advection-diffusion equation.
In this PIMMs-Subproject, we will apply probabilistic machine learning techniques to infer what combinations of model parameters can produce the distinct topographies we observe around the world day. Results from this project will enable geoscientists to identify not only what processes have led to present day topography, but also the sensitivity of diverse environments around the world to future climate, vegetation, and environmental change.
SP 2
Unravelling the ice dynamic, atmospheric and oceanographic history of ice-sheets with Bayesian inference
- Principal Investigators: Reinhard Drews1 · reinhard.drews@uni-tuebingen.de · website
Jakob Macke2 · jakob.macke@uni-tuebingen.de · uni-tuebingen.de/en/196970
- Team member: Guy Moss2 (PhD student)
University of Tübingen, 1Department of Geosciences, 2Cluster of Excellence Machine Learning
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
The Greenland and Antarctic ice sheets are important components in the Earth System impacting climate evolution with their imprints on the global radiation balance and ocean current formation. Ice-sheets models, however, struggle to successfully reconstruct the ice-sheets’ history and have significant uncertainties in predicting their future behavior.
In this PIMMs-Subproject, we will develop and use Bayesian inference methods for ice-flow models.This will open the door to include a thus far fully underused ice-sheet wide archive, and may fundamentally change the way ice-sheet models are initialized, and how uncertainties in the inferred parameters can be used to communicate different historical scenarios compatible with available observations.
SP 3
Efficient inference and simulation for mechanistic models in neuroscience
- Principal Investigators: Philipp Berens1 · philipp.berens@uni-tuebingen.de · berenslab.org
Jakob Macke2 · jakob.macke@uni-tuebingen.de · website
Philipp Hennig3 · philipp.hennig@uni-tuebingen.de · website
- Team member: Jonas Beck1 (PhD student)
1Institute for Ophthalmic Research, Universitätsklinikum Tübingen
University of Tübingen, 2Cluster of Excellence Machine Learning, 3Department of Computer Science
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
In neuroscience, mechanistic models have long been used to understand the biophysical basis of physiological observations. In this PIMMs-Subproject, we aim to enhance the toolkit for the inference of numerical multicompartment models from data and thus contribute to our understanding of the biophysical mechanistic basis of neural processing.
We will do this by exploiting recent advances in probabilistic numerics and simulation based inference to (1) improve our toolkit for fitting multicompartment neuron models when side information is available e.g. from multimodal data sets and (2) to come up with principled techniques to choose simulation parameters for such models such as the time step or the number of compartments with a guaranteed uncertainty bound.
SP 4
Inference of predictive genome wide mechanistic models of cellular differentiation from single-cell transcriptomics with gradient information
- Principal Investigators: Manfred Claassen1 · manfred.claassen@uni-tuebingen.de · website
Jakob Macke2 · jakob.macke@uni-tuebingen.de · website
- Team member: Sebastian Bischoff1 (PhD student)
1Internal Medicine I, Universitätsklinikum Tübingen, 2Cluster of Excellence Machine Learning, University of Tübingen
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Multi-cellular organisms are typically composed of different cell types, each of which are the result of differentiation processes, i.e. cell state transitions from stem- and progenitor cell types to fully differentiated cell types. Single-cell RNA sequencing constitutes a technology that enables recording transcriptomic cell states and has so far been used to infer descriptive models, i.e. sequences of relevant cell states during differentiation.
In this PIMMs-Subproject, we aim at moving one step further and address the task of reconstructing mechanistic models of differentiation from such data. Ultimatively, this may result in a probabilistic inference methodology for a class of parameter estimation and model selection problems for single cell sequencing data, for which standard inference approaches are not applicable.
► Uncovering the inner structure of medical images through generative modeling
Automated analysis of medical image data has undergone impressive developments over the past decade mainly due to the application of deep learning methods for image classification, segmentation and image-based regression. Despite these advances, machine learning (ML) methods are still rarely used in clinical practice due to underperformance in real-life settings.
In this Network Project we want to explore how state-of-the art ML methodology can be applied to medical image data in order to (1) better understand the structure and content of medical images and thus the underlying physiological and pathological processes, (2) assess robustness and safety of ML models for medical image analysis, and (3) increase robustness of ML models for medical image analysis.
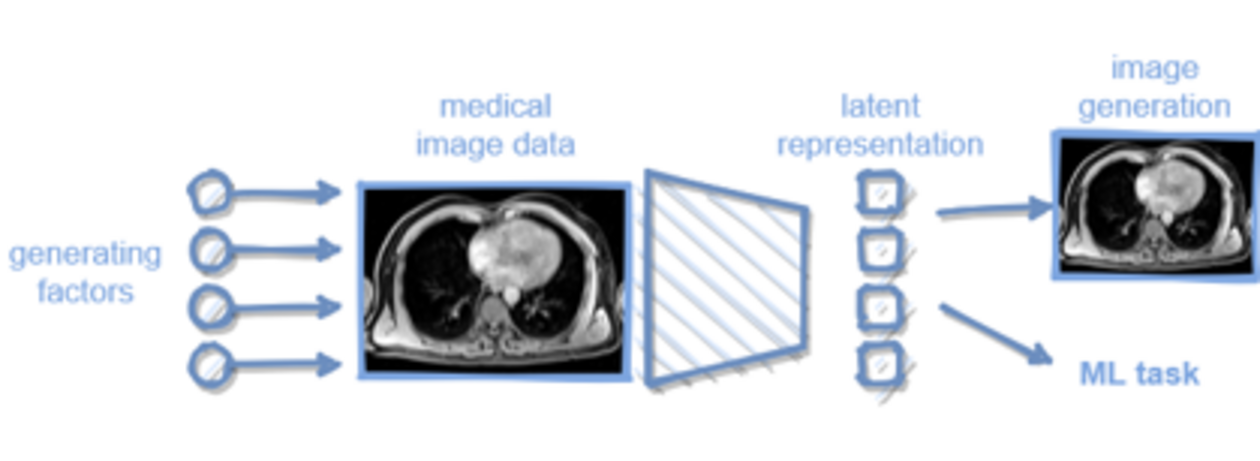
Within 4 Subprojects (SP) we aim at developing probabilistic generative models as well as incorporating determiniscially known factors such as the image generation process where such information is available. In this manner, we will obtain useful data representations for medical image analysis and simplify the modelling process through prior knowledge of deterministic mechanisms. From a medical point of view, we will target different medical image data covering 2D, 3D and 3D+t scenarios including normal and pathological cases.

SP 1
Domain Generalisation for Medical Image Analysis via Causal Representation Learning
- Principal Investigators: Bernhard Schölkopf1· bernhard.schoelkopf@tuebingen.mpg.de · Website
Sergios Gatidis1,2· sergios.gatidis@med.uni-tuebingen.de · Website
- Team member: Sergios Gatidis1
1Max Planck Institute for Intelligent Systems, Tübingen, 2Department for Radiology, Universitätsklinikum Tübingen
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
One of the main factors inhibiting widespread and robust deployment of machine learning algorithms for medical image analysis is the variation of acquired images due to a number of known and unknown factors. In this Subproject, we aim to approach the application of structural causal models to tackle the challenge of covariate shift in medical image analysis. In contrast to natural images, medical images are acquired in a highly standardized way under controlled conditions where data generating factors are at least partially known. We hypothesize that under these circumstances, it can be possible to approach the otherwise hard problem of disentangling mechanisms.
We have the following goals:
(1) Implementation of a causal representation learning framework for high dimensional medical image data aiming for disentangled data representations using independent mechanisms.
(2) Experimental validation of the robustness of such models for typical downstream tasks (e.g. organ segmentation) under covariate shifts.
{kind=link}
SP 2
Assessing the robustness of medical prediction algorithms
- Principal investigators: Christian Baumgartner1· christian.baumgartner@uni-tuebingen.de · Website
Matthias Hein2· matthias.hein@uni-tuebingen.de · Website
- Team member: Nikolas Morshuis1 (PhD student)
University of Tübingen, 1Cluster of Excellence Machine Learning, 2Department of Computer Science
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
One of the biggest challenges currently affecting real-world, deep learning based clinical prediction systems is their lack of robustness to certain types of noise and high confidence predictions on out-of-distribution inputs. In medical imaging, and in particular in MR imaging, data are often subject to domain shifts. Slight variations between acquisition sequences, and even identical acquisition parameters acquired with scanners from different vendors, can lead to systematic changes in the data which adversely affect performance.
In this Subproject, we aim to develop (1) rigorous techniques to assess the robustness of automated medical image analysis systems, (2) a benchmark against which developers of such technology can measure their methods’ resilience to common sources of variation, and (3) techniques for providing provable guarantees for algorithms performance under variations in the image acquisition process e.g. imaging artefacts. At the same time, we will pursue collaborations with clinical groups in Tübingen to validate our methodologies in practical settings.
SP 3
Leveraging anatomical and temporal priors for prediction andunderstanding of disease in high-dimensional medical imaging data
- Principal investigators: Jakob Macke1· jakob.macke@uni-tuebingen.de · Website
Christian Baumgartner1· christian.baumgartner@uni-tuebingen.de · Website
- Team member: Jaivardhan Kapoor1 (PhD student)
1University of Tübingen, Cluster of Excellence Machine Learning
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
The analysis of longitudinal aspects of medical imaging data is key to understanding the progression of diseases such as amyotrophic lateral sclerosis, Alzheimer’s disease, and autism, as well as to designing prognosis and early diagnostic tools. Generative modelling of both the spatial dimension and temporal progression of medical scans could not only allow for more accurate diagnoses, but could also allow for predictions of the future disease progress. Moreover, such analysis may lead to the discovery of novel temporal biomarkers and an improved understanding of disease processes.
In this Subproject, we tackle these challenges by building on recent advances in generative modeling to develop techniques that capture spatio-temporal relations in high-dimensional medical scans. Our goal is to exploit statistical regularities by learning underlying representations which are shared both across subjects and times. Temporal dynamics will be captured using structured state space models combined with neural networks, which has been previously explored in different contexts. Furthermore, conditioning the latent state on additional covariates will allow us to causally incorporate other patient data, such as genetic risk factors, gender or lifestyle choices. In parallel, we will pursue collaborations with clinical groups in Tübingen in order to ultimately bring this technology to clinical practice.
SP 4
Understanding the structure of fundus images in ophthalmologyusing hybrid generative models including the physical imaging process
- Principal investigators: Philipp Berens1· philipp.berens@uni-tuebingen.de · berenslab.org
Hendrik Lensch2· hendrik.lensch uni-tuebingen.de · Website
uni-tuebingen.de · Website
- Team member: Sarah Müller1 (PhD student)
1University Hospital Tübingen, Institute for Ophthalmic Research, 2University of Tübingen, Department of Computer Science
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aim of the project
Photographs of the eye fundus are a standard diagnostic modality in ophthalmology and have received considerable attention from the AI community. Most studies so far have focussed on supervised discriminative learning tasks, where a patient's state is diagnosed based on the fundus image. For representation learning, these images provide a particular challenge, as they have very high resolution and show miniature details that are clinically important. For this reason, simply downsampling the images or generating blurry images is not a viable strategy. Yet, good generative models and appropriate representations are highly desirable to allow for an unsupervised exploration of the manifold of healthy and diseased fundus images.
In this Subproject, we want to (1) develop a new hybrid generative model to learn representations of medical images, which can model fine clinically relevant details and (2) use the learned representations with the disease annotations from NAKO ('National Cohort') to study the structure of the manifold of fundus images in healthy and disease individuals in close collaborations with our clinical partners.