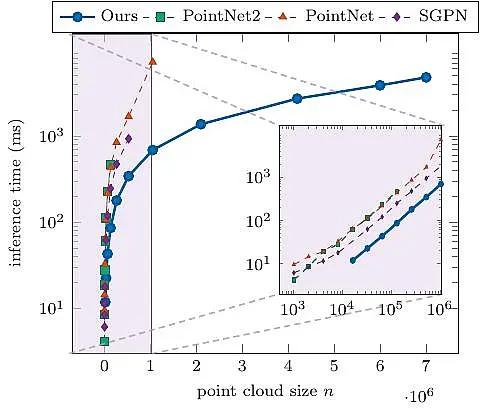
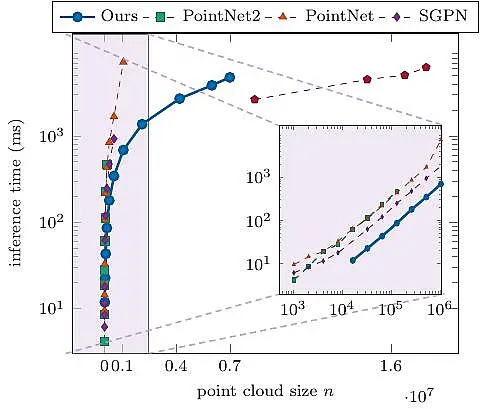
Flex-Convolution
Externer Inhalt
Hier wäre eigentlich ein Video zu sehen. Damit Sie diesen Inhalt (Quelle: www.xyz.de) sehen können, klicken Sie bitte auf "Akzeptieren". Wir weisen Sie darauf hin, dass durch das Abspielen des Videos neben Cookies zur Videowiedergabe auch Cookies des Drittanbieters zu Targeting- und Werbezwecken gesetzt und Informationen ggf. mit weiteren Diensten des Drittanbieters verknüpft werden können. Weitere Informationen und eine Widerrufsmöglichkeit finden Sie in unserer Datenschutzerklärung.

Abstract
Content