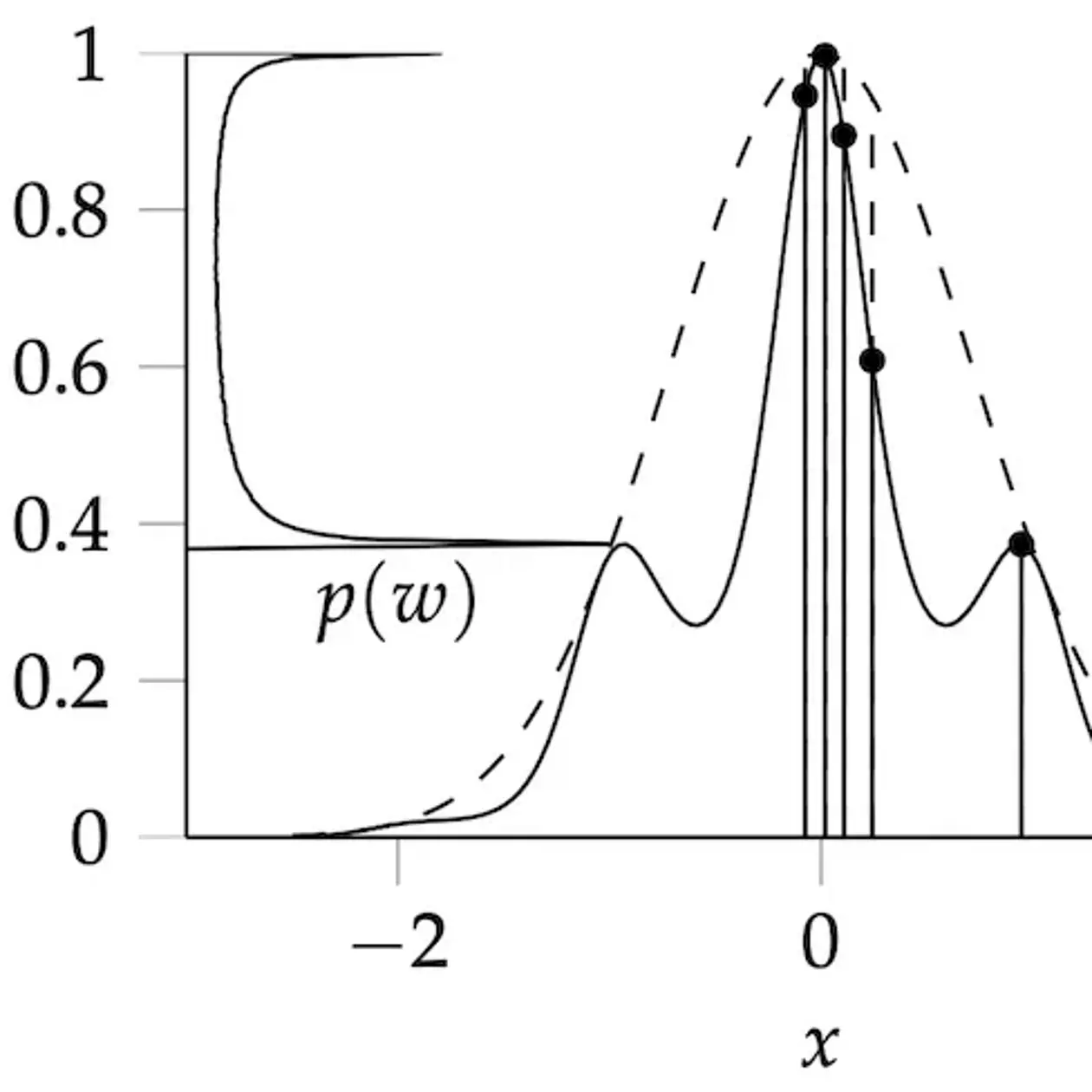
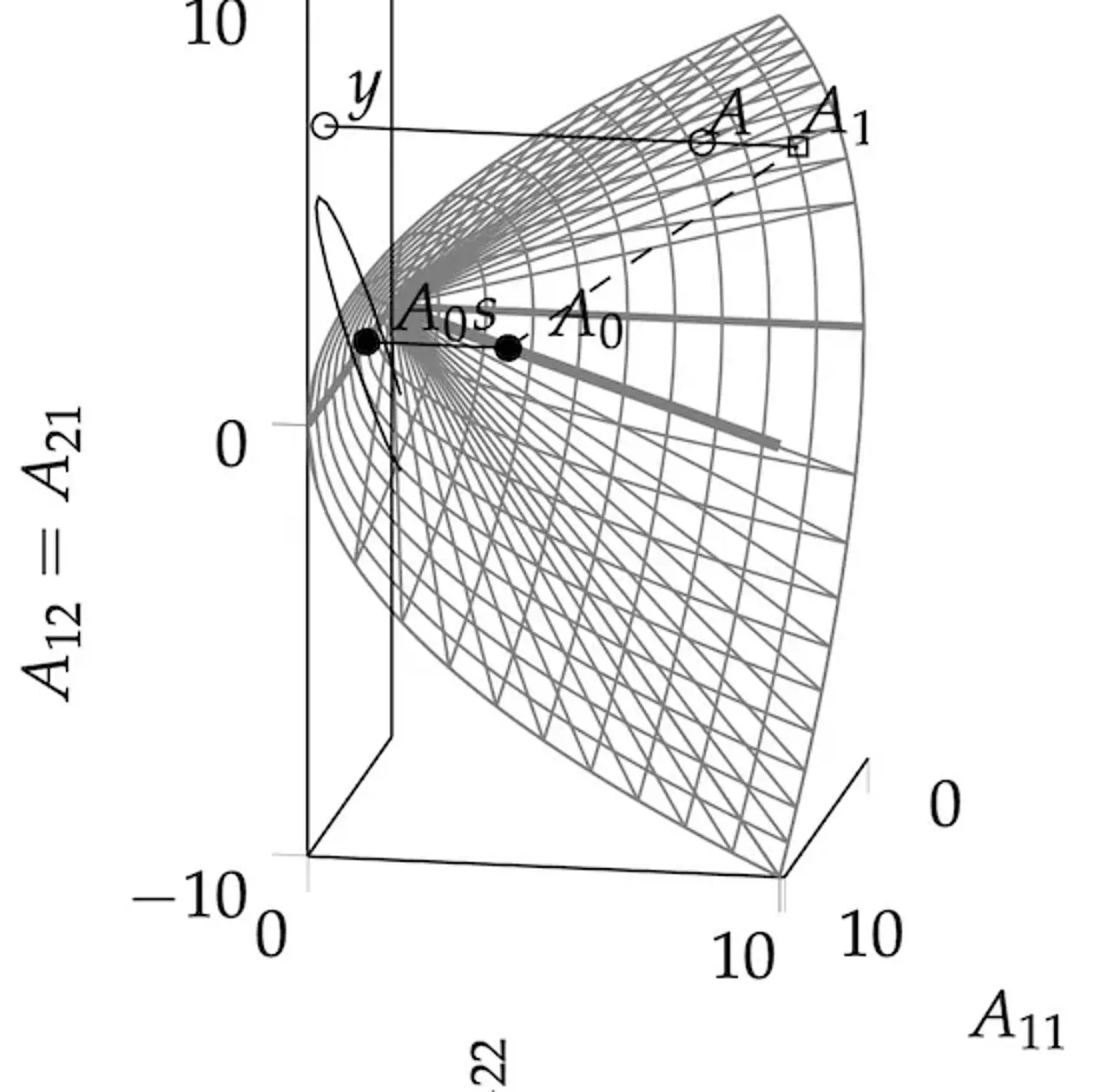
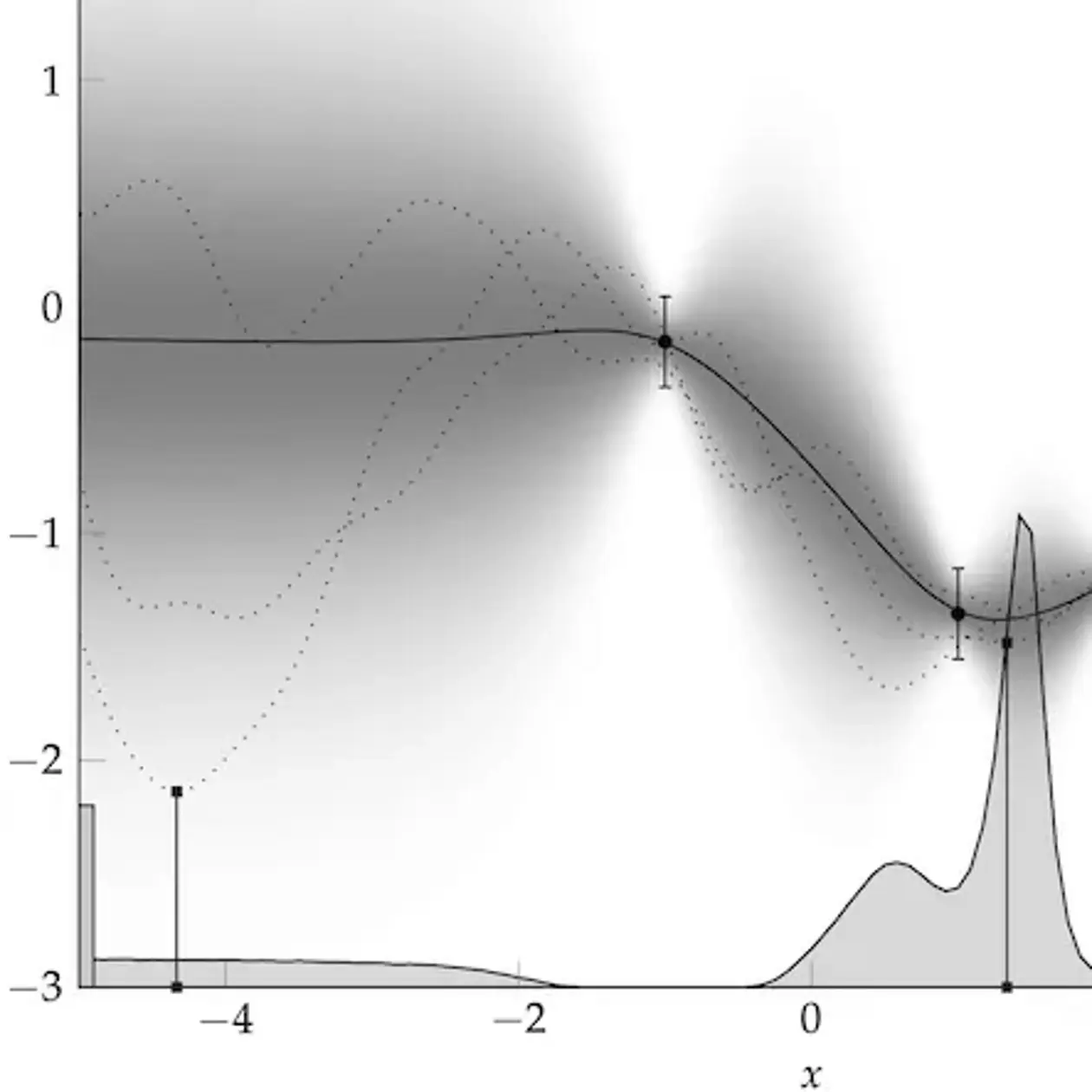
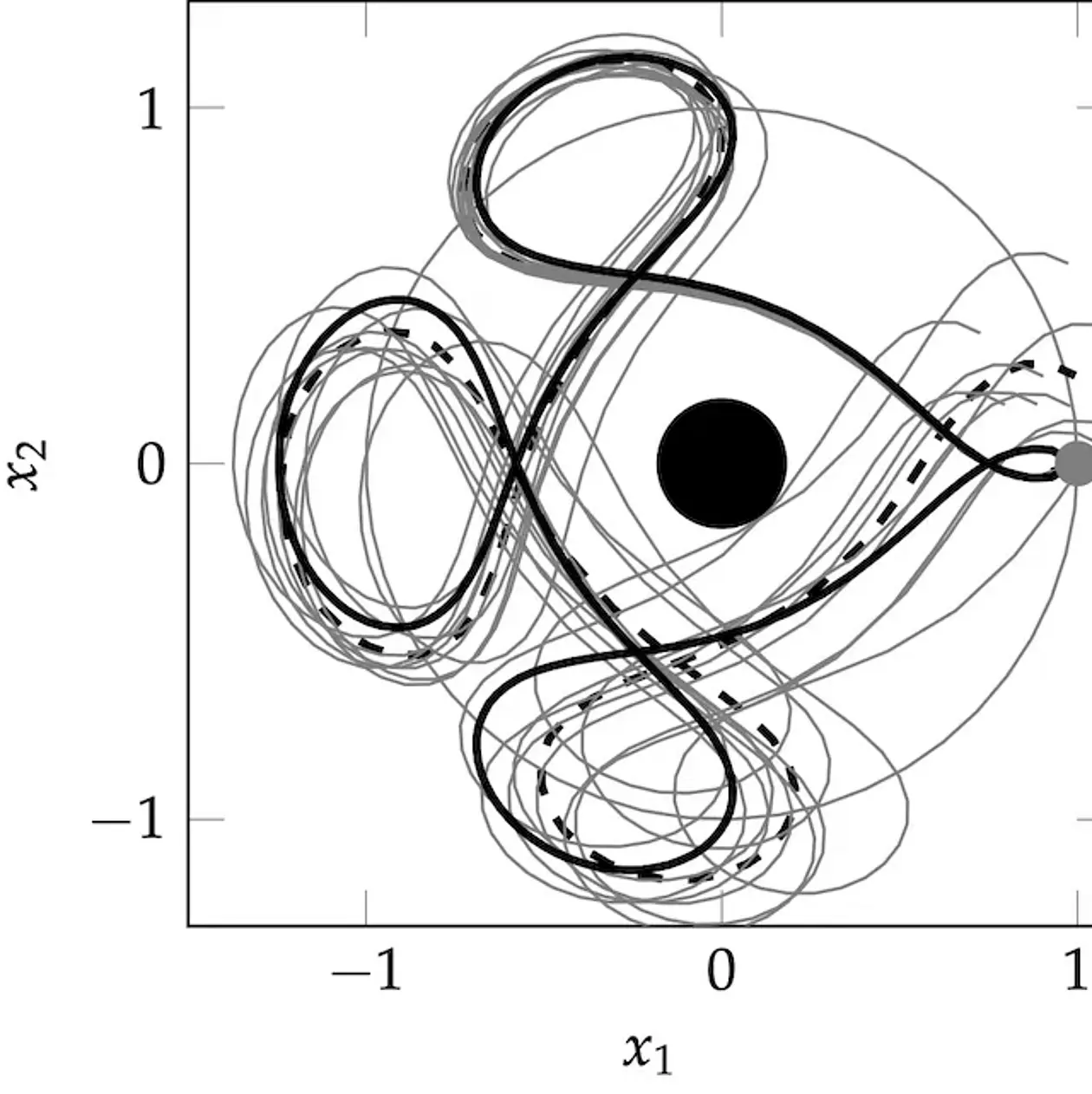
Maschinelles Lernen, im Gegensatz zu klassischer, regelbasierter künstlicher Intelligenz, beschreibt Lernen als statistische Inferenz. Die konkrete Realisierung dieses Lernprozesses in einem Computer verlangt die Lösung numerischer Probleme: Optimierung (die beste Erklärung für Daten finden), Integration (die Menge an möglichen Erklärungen abschätzen) und Simulation (zukünftige Dynamik vorhersagen). Die angewandte Mathematik hat für diesen Zweck gute algorithmische Werkzeuge entwickelt. Der Kerngrundsatz der Arbeit unserer Gruppe ist die Erkenntnis, dass diese numerischen Methoden in sich selbst elementare, lernende Maschinen sind. Eine Lösung numerisch (also mit dem Computer) zu berechnen bedeutet das Ergebnis von digitalen, nicht-analytischen Berechnungen (Daten) zu verwenden, um die unbekannte Zahl zu inferrieren. Da numerische Methoden aktiv entscheiden, welche Berechnungen sie ausführen „möchten“, um effizient zum Ziel zu finden, sind sie tatsächlich auch ``autonome Agenten‘‘, wenn auch in elementarer Form. Also muss es auch möglich sein ihr Verhalten im mathematischen Formalismus lernender Maschinen zu beschreiben. Wenn diese Beschreibung mit Hilfe von Wahrscheinlichkeiten erfolgt, nennen wir die zugehören Algorithmen: „Probabilistische, Numerische Methoden“. Derartige Methoden verwenden ein generatives Model zur Beschreibung numerischer Aufgaben; und konstruieren a-posteriori Verteilungen mit Hilfe von Bayesianischer Inferenz. Diese Wahrscheinlichkeitsverteilungen können dann ``von Außen“ analysiert werden, analog zum Studium der Punktschätzer in klassischer Numerik: Die a-posteriori-Verteilung sollte sich möglichst schnell um den korrekten Wert konzentrieren (ihr Mittelwert sollte nah am echten Wert sein und die Standardabweichung sollte der Distanz zwischen Wahrheit und Durchschnitt entsprechen) und diese Konzentration sollte in einem gewissen Sinne „schnell“ von fortschreiten. Die theoretische Arbeit der Gruppe fokussiert sich auf die Entwicklung solcher Methoden und verwendet sie, um im maschinellen Lernen und allgemeiner dem Datengetriebenen Rechnen neue, dringend benötigte Funktionalität zu bieten.