attempto online
02.03.2022
Sehen Maschinen wie Menschen? Immer mehr!
Eines Tages werden uns Maschinen vielleicht zur Arbeit fahren. In ungewohnten Situationen oder bei verrauschten Daten kommen sie heute allerdings noch ins Straucheln. Das liegt daran, dass Maschinen die Welt ganz anders sehen als wir Menschen. Diese Lücke beginnt sich aber zu schließen.

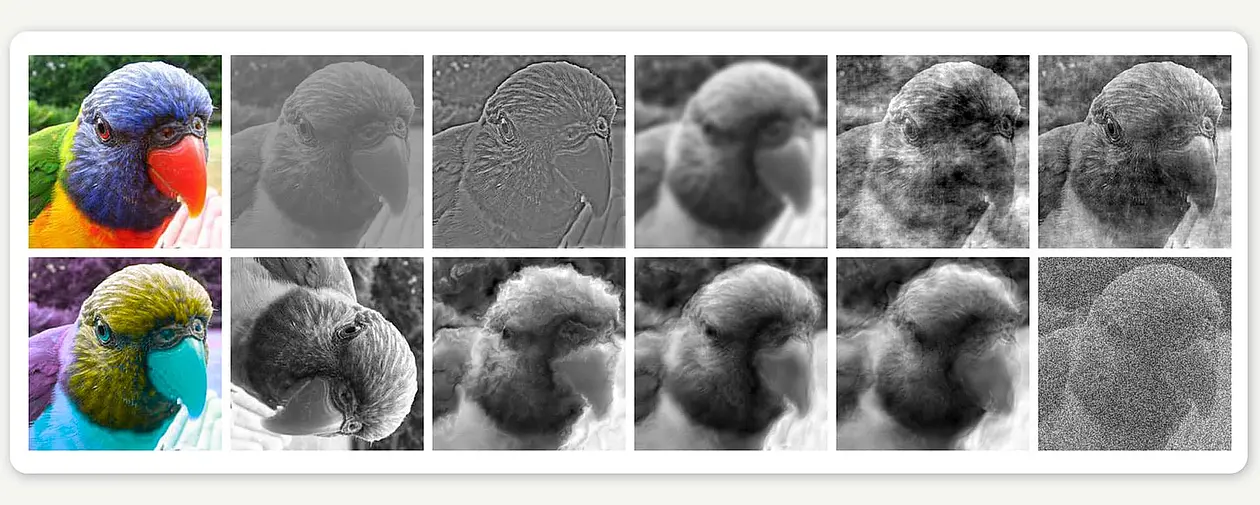
Seit Jahrhunderten träumen wir Menschen von Maschinen, die die Welt so verstehen wie wir; die uns zur Arbeit fahren, das Geschirr spülen oder uns sogar, wie der Star Wars R2D2 Roboter, auf einem Spaziergang begleiten. Damit so etwas je klappen kann, müssen Maschinen jedoch zunächst einmal lernen, Objekte in ihrer Umgebung zu erkennen. Konkret: Sie müssen die Tasse auf dem Tisch oder den Fußgänger an der Kreuzung als das erkennen können, was sie sind. Für uns Menschen ist das eine Selbstverständlichkeit, für Maschinen aber immer noch ganz schön schwer. Dass uns diese Fähigkeit an uns selbst gar nicht auffällt, hat vielleicht auch damit zu tun, dass menschliche Gehirne enorme Ressourcen zur Verarbeitung unseres visuellen Inputs einsetzen.
Bei der Entwicklung robuster maschineller Bilderkennungssysteme stellt sich eine wegweisende Frage: Auf welchem Weg können wir uns erfolgversprechend der menschlichen Fähigkeit, Objekte zu erkennen, annähern? Sollten wir versuchen, all unser biologisches Wissen über Hirnfunktion in die Maschinen zu packen? Oder sollten wir lieber einfach mal beiseitelassen, was wir über perzeptive Vorgänge beim Menschen wissen, und stattdessen die maschinellen Modelle umfassender, die Parameter zahlreicher und die Datensätze fürs Training größer machen, um Fortschritte zu erzielen?

Von der Biologie abkupfern – ein verführerischer Irrweg?

{kind=link}
{kind=link}
Kontakt:
Robert Geirhos
Universität Tübingen
Mathematisch-Naturwissenschaftliche Fakultät
robert.geirhos@uni-tuebingen.de
Teilen




